高级编程语言设计与实现复习
复习指南:
本资料归纳总结了课程课件,仅用于简单复习;如若奔着拿高分满分,还请回归原 PPT 教材。
资料总结借助了
Gemini 3 Pro和ChatGPT 5.1 Thinking的神力,并且由本人简单核查归纳了一下。9/10章,2025 Autumn 没考。
0. 课程导论 (Course Overview)
0.1 编程语言的定义与本质
- 定义:连接现实世界和计算机世界的桥梁,人与计算机交流的工具。
- 交流内容:计算、通信、世界建模。
- 核心观点 (SICP名言):计算机科学本质上是构建恰当描述性语言的学科。
0.2 编程语言的核心关注点
- 易用性(Usability):
- 语言设计(语法、语义、抽象级)。
- 工具支持(IDE、调试、构建)。
- 高性能(Performance):
- 编译器/解释器优化、运行时效率、并行化。
- 软件质量(Reliability/Safety):
- 类型安全、内存安全、并发安全。
- 动静态检查、形式化验证。
1. 编程语言导论 (Introduction)
1.0 编程语言发展史
- 演进路径:机器语言 (0101) -> 汇编语言 -> 高级语言。
- 关键语言里程碑:
- 1957 Fortran:科学计算,第一个高级语言。
- 1958 Lisp:函数式编程鼻祖,AI 领域,引入 GC、Lambda。
- 1967 Simula:面向对象鼻祖。
- 1972 C:系统编程,影响深远。
- 1972 Smalltalk:纯面向对象,消息传递。
- 1995 Java:虚拟机,跨平台,安全性。
- 2010s:Rust (内存安全), Go (云原生), Swift/Kotlin (移动端), TypeScript (前端类型安全)。
1.1 核心概念
-
编程语言的定义:人与计算机交流的工具。
- 人:追求简单、高效、易读(Write & Read)。
- 机器:追求执行效率、资源消耗少(Execute)。
-
三个核心维度:
- 效率(Efficiency):开发效率,表达力强,易于抽象。
- 性能(Performance):运行速度快,内存/能耗少。
- 安全(Safety):类型安全,内存安全,并发安全。
- 权衡(Trade-off):通常难以兼顾三者(如 C++ 重性能轻安全,Python 重效率轻性能)。
1.2 语言分类
- 按应用场景:
- 轻量业务:JS, Python, Lua, Ruby
- 动态脚本语言:“串珠子的绳子”;代码量小、快速编写、解释执行;不追求安全与性能;语言开发容易,种类繁多
- 重业务:Java, Go, C#, Swift
- 静态类型App开发语言:面向开放场景,追求应用生态:吸引开发者;代码规模较大,平衡性能、安全与易用性;静态类型、类型安全、自动内存管理
- 系统编程:C, C++, Rust
- 性能优先,底层控制能力(内存/硬件),对开发者要求高。
- 轻量业务:JS, Python, Lua, Ruby
- 按计算模型/编程风格:
- 命令式(Imperative):
- 计算模型:图灵机;
- 通过命令序列修改机器状态(变量赋值)完成计算。
- 例:C, Java, Go
- 函数式(Functional):
- 计算模型:
- 通过函数组合完成计算,强调无副作用,数据不可变。
- 例:Lisp, Haskell, ML
- 计算模型:
- 面向对象(Object-Oriented):
- 数据 (属性)与计算 (行为)封装。
- 例:Smalltalk, Java
- 逻辑式(Logic):基于谓词逻辑。例:Prolog
- 命令式(Imperative):
- 按执行方式:
- 静态编译(Static Compilation):源码 -> 机器码 -> 硬件执行。
- 优点:快;
- 缺点:开发周期长,难以动态修改。
- 例:C, C++, Rust
- 动态解释(Dynamic Interpretation):源码 -> 解释器/虚拟机执行。
- 优点:灵活,跨平台;
- 缺点:慢。
- 例:Python, JS
- 字节码/虚拟机(Bytecode/VM):源码 -> 字节码 -> 虚拟机 (JIT编译为机器码)。
- 折中方案。
- 例:Java, C#, Lua
- 静态编译(Static Compilation):源码 -> 机器码 -> 硬件执行。
- 按类型系统:
- 静态类型 vs 动态类型:编译期检查 vs 运行期检查。
- 强类型 vs 弱类型:是否允许隐式类型转换(弱类型如 C/C++ 允许指针乱转,不安全)。
1.3 编程范式 (Paradigms)
-
命令式(Imperative):
- 关注 “怎么做”(How)。
- 基于图灵机,冯·诺依曼模型,通过修改状态(变量赋值)完成计算。
- 典型:C, Pascal, Assembly。
-
面向对象(OO):
- 封装数据(属性)与行为(方法)。
- 核心:封装、继承、多态。
- 典型:Java, Smalltalk。
-
函数式(Functional):
- 关注 “做什么”(What)。
- 基于
- 核心:高阶函数、闭包、模式匹配。
- 典型:Haskell, Lisp, ML。
1.4 语言发展趋势
-
多范式融合:OO与FP的界限模糊,如Rust、Scala、Swift。
-
安全性增强:
- 内存安全:Rust的所有权机制。
- Null Safety:消除“十亿美元的错误”(Null Pointer Exception),如Kotlin, Swift, Cangjie中的
Option/?类型。
-
类型系统进化:从动态向静态靠拢(TypeScript, Python Type Hints),Gradual Typing(渐进式类型)。
-
大模型的影响:自然语言不会完全取代编程语言,因为编程语言是无二义性的数学语言,是精确表达逻辑的工具。未来编程语言需更易于AI生成和人类审核(易读 > 易写)。
2. 仓颉语言概览 (Cangjie Overview)
仓颉是一门多范式、静态强类型、高性能的现代编程语言。
2.1 基础语法
-
变量与常量:
var: 可变变量 (Variable)。- 支持类型推断:
var x = 0(推断为 Int64 )
- 支持类型推断:
let: 不可变变量 (Value),运行时求值。const: 常量,编译时求值。
-
类型:
-
基础类型:
-
整数 (
Int64,UInt8…), 浮点 (Float64), 布尔 (Bool). -
字符串 (
String)- 多行字符串字面量开头结尾需各存在三个双引号(
""")或三个单引号(''')。 - 多行原始字符串字面量以一个或多个井号(
#)和一个单引号(')或双引号(")开头,后跟任意数量的合法字符,直到出现与字符串开头相同的引号和与字符串开头相同数量的井号为止。转义规则不适用于多行原始字符串字面量,字面量中的内容会维持原样。
1
2
3
4
5
6
7
8
9let s2 = '''
Hello,
Cangjie Lang'''
let s3 = ##'#'\n'## // 输出结果为:#'\n
let s4 = ###"
Hello,
Cangjie
Lang"### // 该变量当中的换行、缩进等也会被保留 - 多行字符串字面量开头结尾需各存在三个双引号(
-
字符 (
Rune,支持以 Unicode 值定义字符)- 一个
Rune字面量由字符r开头,后跟一个由一对单引号或双引号包含的字符。 - 转义字符使用转义符号
\开头,后面加需要转义的字符。let newLine: Rune = r'\n' - 通用字符以
\u开头,后面加上定义在一对花括号中的 1~8 个十六进制数,即可表示对应的 Unicode 值代表的字符。
1
2
3
4
5
6main() {
let he: Rune = r'\u{4f60}'
let llo: Rune = r'\u{597d}'
print(he) // 你
print(llo) // 好
}- 支持字符的 Unicode 值进行比较
- 一个
-
数组 (
Array<Rune>) -
元组 (
(Int64, Float64))- 元组的长度是固定的,即一旦定义了一个元组类型的实例,它的长度不能再被更改。
- 元组类型是不可变类型,即一旦定义了一个元组类型的实例,它的内容(即单个元素)不能再被更新。但整个元组可被覆盖替换
-
区间 (
Range<Int64>, 0…10):区间类型用于表示拥有固定步长的序列,区间类型是一个泛型,使用Range<T>表示。最常用的Range<Int64>用于表示整数区间。-
Range<T>(start: T, end: T, step: Int64, hasStart: Bool, hasEnd: Bool, isClosed: Bool) -
区间字面量有两种形式:“左闭右开”区间和“左闭右闭”区间。
- “左闭右开”区间的格式是
start..end : step,它表示一个从start开始,以step为步长,到end(不包含end)为止的区间; - “左闭右闭”区间的格式是
start..=end : step,它表示一个从start开始,以step为步长,到end(包含end)为止的区间。 - 区间字面量中,可以不写
step,此时step默认等于1。但是step的值不能等于0
- “左闭右开”区间的格式是
1
2
3
4
5
6
7
8
9
10
11
12let r22 = Range<Int64>(0, 10, 1, true, true, false) // r22 contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
let n = 10
let r1 = 0..10 : 1 // r1 contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
let r2 = 0..=n : 1 // r2 contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
let r3 = n..0 : -2 // r3 contains 10, 8, 6, 4, 2
let r5 = 0..10 // the step of r5 is 1, and r5 contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
let r6 = 0..10 : 0 // Error, step cannot be 0
let r7 = 10..0 : 1 // empty ranges -
-
Unit:类似
void,字面量为()。除了赋值、判等和判不等外,Unit类型不支持其他操作。 -
Nothing:是一种特殊的类型,它不包含任何值,并且
Nothing类型是所有类型的子类型。break、continue、return和throw表达式的类型是Nothing,程序执行到这些表达式时,它们之后的代码将不会被执行。return只能在函数体中使用,break、continue只能在循环体中使用。
-
-
Option 类型 (
Option<T>相当于?T):解决空指针问题。值要么是Some(T),要么是None。- 解包:
getOrThrow(),match匹配。
- 解包:
-
2.2 流程控制
- 一切皆表达式:
if,match,try-catch, 代码块{}都有返回值(即最后一条语句的值)。 - Match 表达式 🔥:
- 支持常量模式、类型模式、绑定模式 (
case Red(v)),where守卫。 - 编译器检查穷尽性 (Exhaustiveness)。
- 支持常量模式、类型模式、绑定模式 (
2.3 函数 (Functions)
-
定义:
func name(p1: T1, p2!: T2): RetType { ... } -
命名参数:
p2!: T2表示调用时必须写参数名 (name(1, p2: 2))。func f(x!: Int)-> 调用f(x: 1)。- 命名参数还可以设置默认值,只能为命名参数设置默认值,不能为非命名参数设置默认值。
- 参数列表中可以同时定义非命名参数和命名参数,但是需要注意的是,非命名参数只能定义在命名参数之前。
-
一等公民:函数可以赋值给变量,作为参数或返回值。
-
Lambda 表达式:
{ p1 => body }。支持尾随 Lambda (Trailing Lambda) 语法(如果最后一个参数是函数,可写在括号外)。 -
管道操作符:
|>(e.g.,data |> fn1 |> fn2)-
语法:
e1 |> e2。官方给出的语法糖展开是:let v = e1; e2(v)e1只会求值一次(先存到临时变量v)e2必须是函数类型的表达式,并且e1的类型要能传给e2的参数(子类型关系也可以)
-
|>的优先级比较低(在??之后、赋值之前),并且是左结合,也就是a |> f |> g会按(a |> f) |> g结合。
-
2.4 代数数据类型与模式匹配
-
Enum(Sum Types):
代码段
1
2
3
4enum Expr {
| Number(Float64)
| Add(Expr, Expr) // 递归定义
} -
Pattern Matching:
代码段
1
2
3
4
5match (expr) {
case Number(v) => v
case Add(a, b) => ...
case _ => ... // 通配符
} -
Option 类型:
Option<T>分为Some(T)和None。使用getOrThrow或match处理。
2.5 面向对象与类型系统
-
Struct(结构体):
- 值类型,Copy语义,栈分配。
- 不能继承,但可以实现接口。
mut修饰符:修改struct成员的函数必须标记为mut。
-
Class(类):
- 引用类型,Reference语义,堆分配。
open关键字:修饰类表示可继承,修饰成员表示可覆盖 (override)。
-
Enum(枚举):Sum Type(和类型)。
- 可以携带参数(关联值),支持成员函数和属性。
- 例:
enum Expr { Num(Float64) | Add(Expr, Expr) }。
-
Interface(接口):定义行为规范,支持默认实现。
-
扩展(Extend):
extend String { ... },可以为已有类型(包括系统类型)添加方法或实现接口,不改变原有类定义。 -
Prop(属性):
prop关键字,通过get/set访问,封装字段。
2.6 泛型 (Generics)
- 支持类型参数:
class List<T> where T <: ToString。 - 支持泛型约束 (
where)。
2.6 并发 (Concurrency)
- 模型:M:N 轻量级线程模型,用户线程(协程)映射到少量系统线程。
- 关键字:
spawn { ... }:启动一个新线程(协程)。Future<T>:spawn的返回值,代表未来的计算结果。future.get():等待结果(同步点)。
2.7 宏 (Macros)
- 编译期代码生成与转换。
- 输入
Tokens,输出Tokens。 - 用途:代码插桩、DSL实现(如LINQ)、静态反射。
2.8 跨语言互操作 (FFI)
- C Interop:
@Cstruct 映射 C 结构体。foreign func声明 C 函数。unsafe块中调用 C 函数。- 类型映射:
Int64<->long,CString<->char*.
3. 作用域与函数运行时 (03-Scopes)
3.1 代码块与作用域(Blocks & Scopes)
内联(in-line):代码出现的位置就是它被执行的位置
作用域 (Scope) vs 生存期 (Lifetime)
- 作用域:变量在代码文本中可见的区域(静态概念,看代码即可确定)。
- 遮蔽:内部块可以遮蔽 (Shadow) 外部块的同名变量。
- 生存期:变量在运行时占有内存的时间段(动态概念,运行时决定)。
3.2 活动记录 (Activation Record / Stack Frame)
- 定义:函数调用时,保存在运行时栈上的数据结构,存储单次调用信息(局部变量)。
- 内容:
- 参数(Parameters):调用者传递的值。
- 局部变量(Locals):函数内定义的变量。
- 返回地址(Return Address):函数结束后跳回代码段的哪里。
- 函数返回时,在上一级活动中保存返回值地址
- 动态链(Control Link / Dynamic Link):指向调用者 (Caller) 的活动记录。用于函数返回时恢复栈顶指针 (EBP/ESP)。
- 静态链(Access Link / Static Link):指向定义该函数的外层环境的活动记录。用于实现静态作用域(访问非局部变量)。
3.3 作用域规则
- 静态作用域(Static/Lexical Scoping):
- 变量引用取决于函数定义的位置。变量查找走 Access Link(静态链),它连的是“词法外层(定义位置)”
- 现代语言(C, Java, Python, Cangjie)几乎都使用静态作用域。
- 实现:通过 Access Link 向上查找。
- 动态作用域(Dynamic Scoping):
- 变量引用取决于函数调用的位置。变量查找走 Control Link(动态链),它连的是“调用者(调用位置)”
- 例子:Shell脚本, Emacs Lisp, Perl (local)。
- 实现:通过 Control Link 向上查找。
3.4 参数传递 (Parameter Passing)
- 传值(Call by Value):复制右值(R-value)。Cangjie, Java, C采用此方式。Callee无法修改Caller的变量本身。
- 传引用(Call by Reference):传递左值(L-value/地址)。Callee可以修改Caller的变量。
3.5 尾调用与尾递归 (Tail Call & Tail Recursion)
- 定义:函数
- 优化:不需要为
- 意义:尾递归为特殊的尾调用,可以将递归转化为循环,避免栈溢出(Stack Overflow)。
3.6 高阶函数与闭包 (Higher-order Functions & Closures)
-
高阶函数:函数作为参数或返回值。
-
函数作为参数:需要传递函数代码指针 + 环境指针 (Access Link),指向栈上函数定义处的活动记录。
-
函数作为返回值:需要赋值并额外保存函数定义处的活动记录(Closure 的环境)
- “赋值”:让返回的函数成为一个可达对象,而不是一个瞬间即死的临时值。
- 问题:返回的函数可能引用了已退出函数的局部变量(栈上数据已销毁)。
- 栈失效(Stack Limitation):传统的栈式内存管理无法支持函数作为返回值。
- 解决方案:闭包(Closure) = 代码 + 环境。环境必须分配在堆(Heap) 上,通过 GC 管理。
-
闭包(Closure):
- 定义:代码(Code) + 环境(Environment)。
- 必要性:当函数作为一等公民(First-class)被传递时,它可能引用了定义处的自由变量(Free Variables)。必须把定义时的环境(Access Link指向的记录)打包带走。
- 难点:当函数作为返回值返回时,其依赖的栈帧可能已被销毁。
- 解决方案:将活动记录分配在堆(Heap 上,配合垃圾回收(GC)。
4. 类型系统 (04-Types)🔥
4.1 类型系统的作用
- 安全性:提供一组约束,避免非法操作。
- 可读性:让程序更好读,更易维护。
- 优化:编译器利用类型信息做更多优化。
4.2 类型的分类
-
分类:
-
基本类型:Int, Float, Bool 等
-
复合类型:
-
Array, Struct, Class 等
-
积类型、和类型
-
-
4.2.1 代数数据类型 (Algebraic Data Types, ADT)
积类型
- 积类型 (Product Types):pairs and tuples, 多元 tuple 可以看成是 pair 的泛化。
-
- 我们需要
- 我们需要
- 例子:
- Tuple
(Int, Float), - struct / records 可以看做是带标签的tuple(即labelled tuples)
-
- Tuple
unit类型:代数中的 “1”- 定义:
unit类型只有一个值,通常写作()。 - 视作特殊的 Tuple:图片提到它可以被视作特殊的 tuple 类型(空元组)。在很多语言(如 Rust, Haskell, Swift)中,它就是空的圆括号
()。 - 代数性质:
- 解释:就像数学里的
- 如果你有一个 Pair,其中一个是类型
unit,形式如(value, ())。因为()是唯一且确定的,所以这个 Pair 包含的信息量并没有增加,它等价于只有
- 解释:就像数学里的
- 作用:
- 表示“无返回值”:类似于 C/Java 中的
void。当一个函数只执行副作用(如打印、修改全局变量)而不产生具体计算结果时,它实际上返回的是unit(即“完成”这一单一状态)。 - 泛型占位符:比如你需要一个
Map<Key, Value>来实现一个Set<Key>,你可以定义为Map<Key, Unit>,这样就只有键而忽略了值。
- 表示“无返回值”:类似于 C/Java 中的
- 定义:
-
和类型
-
和类型 (Sum Types):sum types and enum。
-
- 我们需要
- 我们需要
- 语法定义:这两行定义了我们在语言中怎么写求和类型。
- (Types)
- 这表示:一个类型
- 例子:
Int + String。
- 这表示:一个类型
- (Terms)
- 这表示:在这个类型系统中,有三种新的表达式写法:
left e:把值right e:把值case ...:用来根据标记处理这两种情况(类似于switch或match)
- 这表示:在这个类型系统中,有三种新的表达式写法:
- (Types)
- 例子:C中的
union(不安全),Rust/Swift/Cangjie中的enum(带参数的枚举)。 - 模式匹配 (Pattern Matching) 是处理和类型的标准方式。
-
-
示例(伪代码)
规则 伪代码示例 let x: Int = 5; let y: Int + String = left(x);let s: String = "Hello"; let z: Int + String = right(s);case y do {(i: Int) -> return i + 1(这里的(s: String) -> return s.length(这里的}
结果类型: -
nothing类型:代数中的 “0”- 定义:图片指出
nothing类型 没有值(No value)。这意味着你永远无法创建一个该类型的实例变量。在不同语言中它可能叫Never(Rust/Swift),Nothing(Scala), 或Void(Haskell/Logic)。 - 视作特殊的 Sum:图片提到它可以视作 0个分支的 sum 类型。如果你定义一个枚举(Enum),但里面一个成员都不写,那它就是
nothing。 - 代数性质:
- 解释:就像数学里的
- 求和类型表示“要么是 A,要么是 B”。如果 B 是
nothing(不可能存在),那么这个类型实际上只能是 A。
- 解释:就像数学里的
- 作用
- 表示“函数不返回”:注意这与
unit不同。unit表示“函数正常结束但没带回数据”,而nothing表示“控制流永远回不到调用者”。例如:- 无限循环
while(true) {}。 - 程序崩溃或退出
exit()。 - 抛出异常
throw e。
- 无限循环
- 死代码消除:编译器知道如果代码走到了
nothing类型的地方,后面的代码就绝对不可能被执行,因此可以优化掉或报警告。 - 类型系统的完整性:在
case表达式中,如果一个分支是nothing,它就不需要返回值,因为它根本不会正常结束。
- 表示“函数不返回”:注意这与
- 定义:图片指出
4.2.2 函数类型
类型推断
核心概念:Typing Context (类型上下文) 与 Judgment (判断)
- Judgment 类型判断:
- 读作:在环境
- 读作:在环境
- Typing Context (
- 定义:
- 结构:
-
-
-
- 定义:
- 规则示例:
- If-Else: 如果
if表达式类型为 - App (函数应用): 如果
- If-Else: 如果
函数类型
函数定义规则 (Abstraction / Introduction)
这是第一条规则,描述了如何创建一个匿名函数(Lambda):
-
含义:如果你想证明一个函数
-
前提 (分子):你需要做一个假设。假如允许我们引入一个新的、类型为
-
结论 (分母) :在当前的类型环境
-
- 含义:这是我们要检查的代码主体——一个匿名函数定义(Lambda Abstraction)。
-
-
-
- 总结:这一段是在说“这个定义了参数
-
-
直观理解:编译器会说:“我假装
Int -> String。”
函数应用规则 (Application / Elimination)
这是第二条规则,描述了如何调用一个函数:
- 含义:如果你要调用函数
- 前提(分子):
- 检查
- 检查参数
- 检查
- 结论(分母):如果上述两条都满足,那么调用结果
变量查找规则 (Variable)
这是第三条规则(最下面那条横线),它是递归推导的基准情况(Base Case):
-
注意:这条规则上方没有前提(或者说前提是空的),意味着这是公理。
-
含义:如果在当前的上下文(环境)中,已经记录了
-
作用:当你推导到代码的最底层(变量名)时,你需要去查表 (
4.3 类型系统特性
- 强类型 vs 弱类型:是否允许隐式的、不安全的类型转换(如C语言把int当指针用是弱类型行为;Cangjie/Java是强类型)。
- 静态类型 vs 动态类型:
- 静态:编译期检查,性能高,安全。
- 动态:运行期检查,灵活。
- Null Safety:
- 传统:
Null也是一种值,容易导致崩溃。 - 现代(Cangjie/Rust):使用
Option<T>(Sum Type:Some(T) | None),强制程序员处理空值情况。
- 传统:
5 类型推导与 Hindley-Milner 算法 (05-Types-Hindley-Milner)🔥
核心目标:在不写类型标注的情况下,自动推导出最通用的类型(Most General Type / Principal Type)。
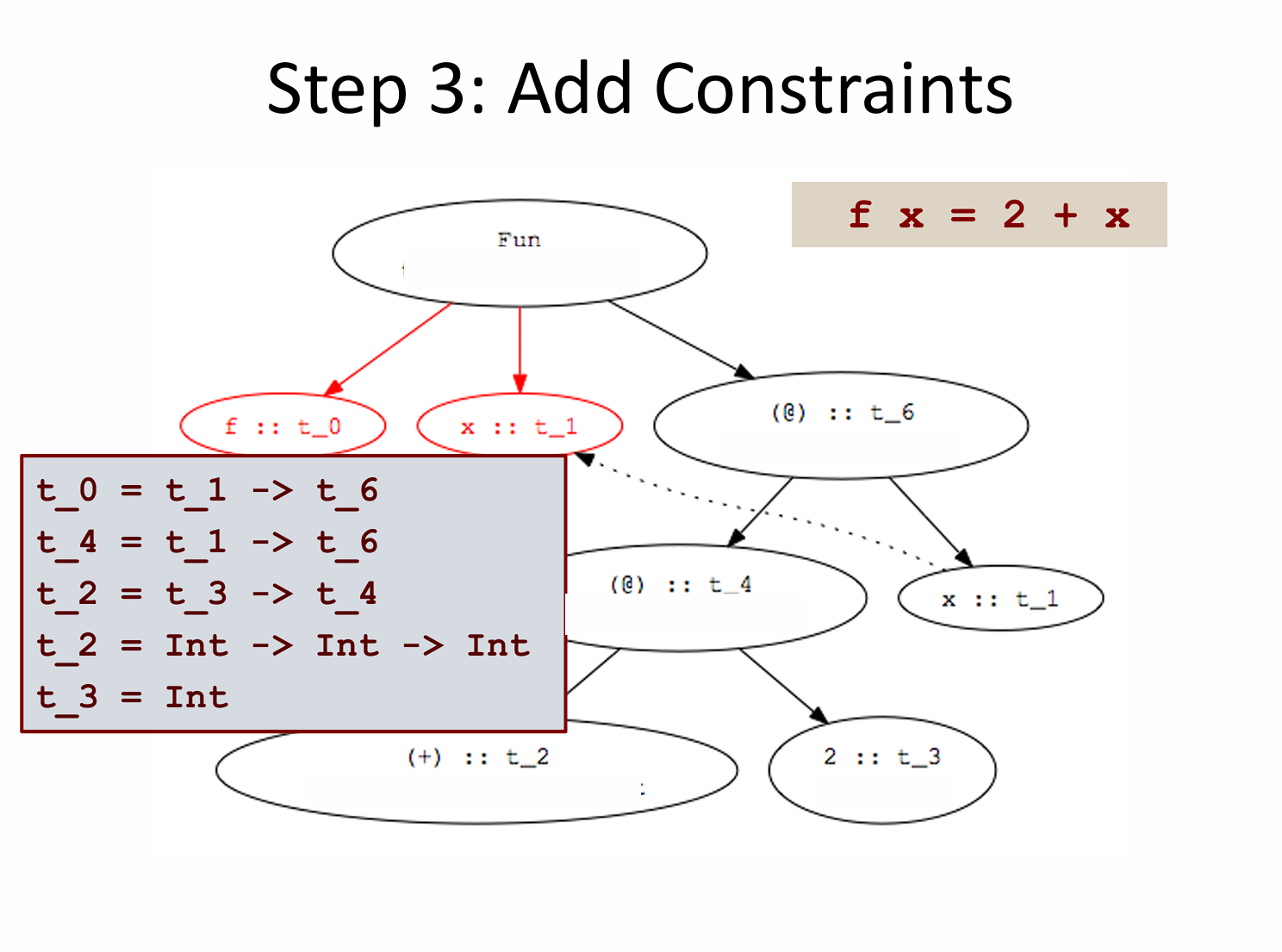
5.1 算法流程 (以 f x = 2 + x 为例)
-
解析(Parse):构建语法树(AST)。将中缀表达式转换为柯里化的函数应用
((+) 2) x。- 中缀转前缀:从
2 + x变成(+) 2 x。 - 柯里化(Currying)拆解:从
(+) 2 x变成((+) 2) x。
- 中缀转前缀:从
-
分配类型变量(Assign Type Variables):
- 给AST中的每个节点分配一个唯一的类型变量(如
-
-
-
-
-
-
- 给AST中的每个节点分配一个唯一的类型变量(如
-
生成约束(Generate Constraints):
-
函数应用(Application)
- 调用
+: - 逻辑:我们手里有一个函数
- 调用
-
函数定义(Abstraction)
fun x -> e:如果- 定义
fun x -> e - 逻辑:既然输入参数是
- 定义
-
根据语法规则建立等式。
-
对于常量
2:我们已知对于操作符
+:我们已知对于应用
(+) 2:- 这是一个函数应用。函数是
+(2( - 根据函数应用规则:函数类型 = 参数类型
- 约束 1:
+ 2的中间结果为
对于应用
((+) 2) x:- 函数是
(+) 2(x( - 约束 2:
对于函数定义
f x = ...:- 这是一个函数定义 (Abstraction)。参数是
- 根据函数定义规则:函数整体类型 = 参数类型
- 约束 3:
- 这是一个函数应用。函数是
-
-
-
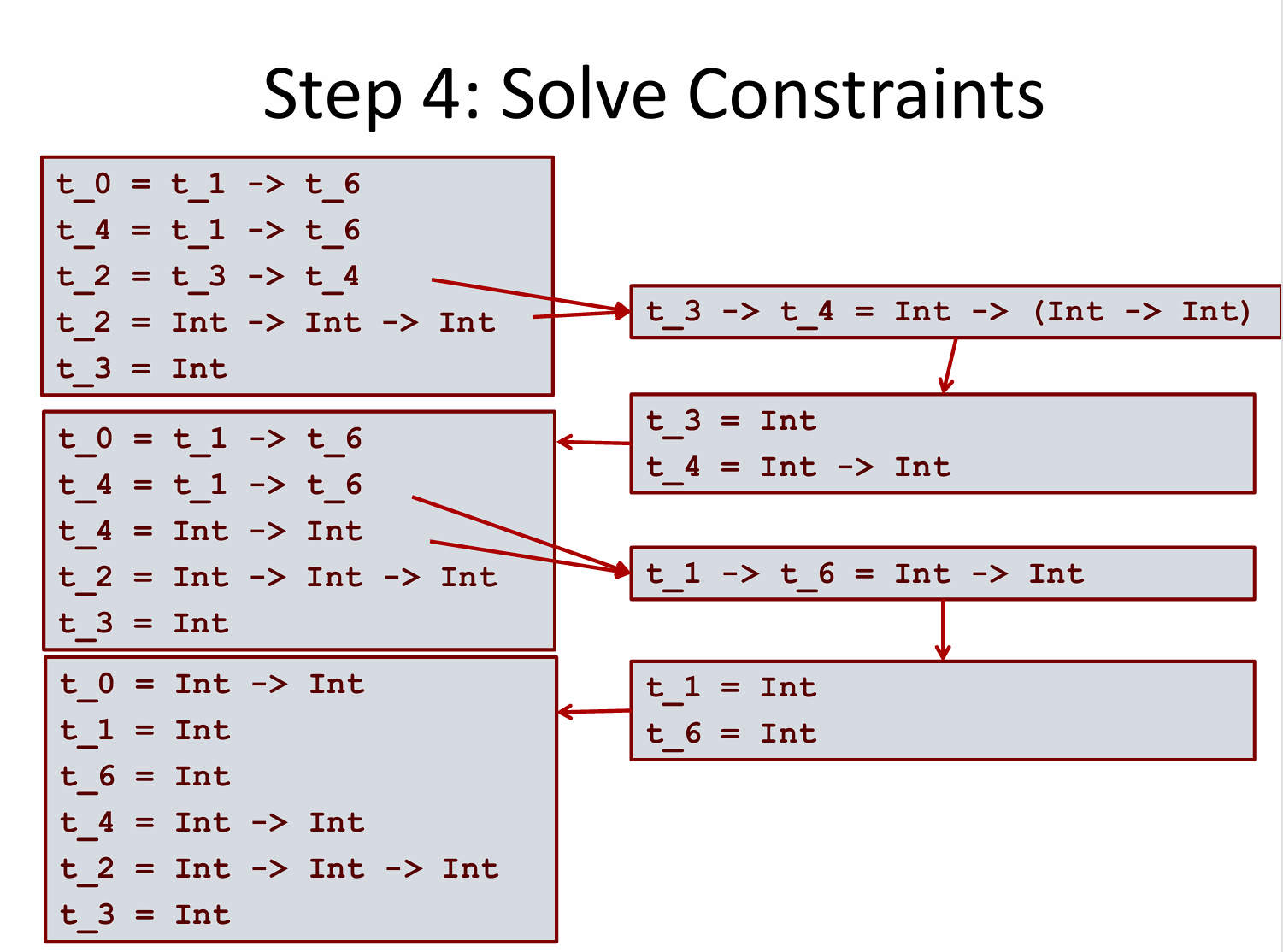
解约束(Solve Constraints):
-
使用 Unification (统一) 算法求解方程组。
- 从约束 1 (
- 已知
- 已知
- 代入方程:
- 解得:
- 已知
- 解约束 2 (
- 代入
- 对比箭头左边:
- 对比箭头右边:
- 代入
- 解约束 3 (
- 代入
- 最终结果:
- 代入
结论:
f的类型推导为Int -> Int。 - 从约束 1 (
-
-
确定最终类型:
- 无法被约束为具体类型(如Int)的变量保留为类型参数(如
- 无法被约束为具体类型(如Int)的变量保留为类型参数(如
5.2 多态 (Polymorphism)
-
Let-polymorphism(Let 多态):Hindley-Milner算法支持
let绑定的多态。let id = \x -> x,类型为- let 绑定:
let关键字标志着一个值的定义完成,此时编译器会检查这个值或函数是否包含任何尚未确定的类型变量。如果有,编译器就会将其泛化(generalize),使其成为多态类型。 id:是这个函数的名称(通常称为 Identity Function,恒等函数)。\x -> x:这是函数的定义(\x表示) 接收一个输入x,并原封不动地返回x。-
-
-
- let 绑定:
- 推导过程:
- HM 算法分析函数体
x,得出id的类型是 - 算法发现
Int)约束。 - 因此,在
let绑定时,算法将
- HM 算法分析函数体
id 3(Int) 和id true(Bool) 可以在同一作用域内有效。- 当执行
id 3时 ( - 当执行
id true时 (
- 当执行
-
最通用类型(Principal Type)
-
HM算法保证只要程序在逻辑上是类型正确的,一定能推导出最通用的那个类型。
- 最通用:意味着推导出的类型具有最大的泛型潜力。
-
例如,如果一个函数只是简单地对一个列表进行操作,它不需要知道列表里具体是什么类型。
- 推导出
List<T>而不是List<Int>,除非用法限制了它必须是Int。
- 推导出
-
何时丧失通用性?
只有当代码用法对类型施加了新的约束时,HM 才会把通用变量(- 例: 如果你写了一个函数
f(list) = list * 2(伪代码,对列表执行标量乘法),那么:*操作符的类型是- 算法立即约束:
list里的元素必须是 - 此时,算法推导出的类型就会从
- 例: 如果你写了一个函数
-
5.3 构建分析树的类型推导(PPT内容展示)🔥
需要明确的:
-
λ/fun/Fun节点**:表示**函数抽象(定义函数) -
@节点**:表示**函数应用(调用函数)如果
那么
整体(@节点):
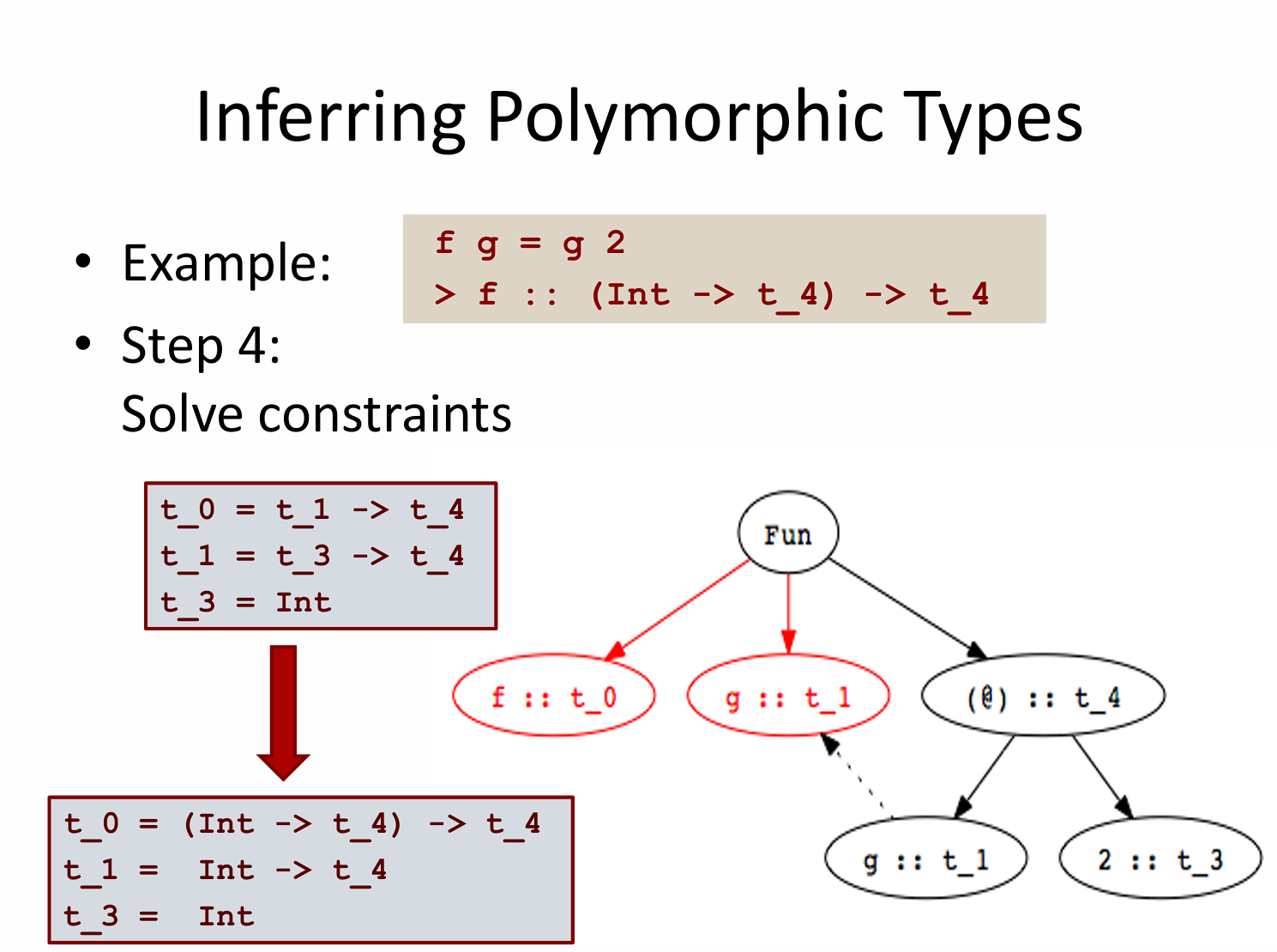
再来看看如下推断: f g = g 2 👇
f的返回值类型 和g的返回值类型完全一致f对返回类型多态,因为它对t没有任何约束。

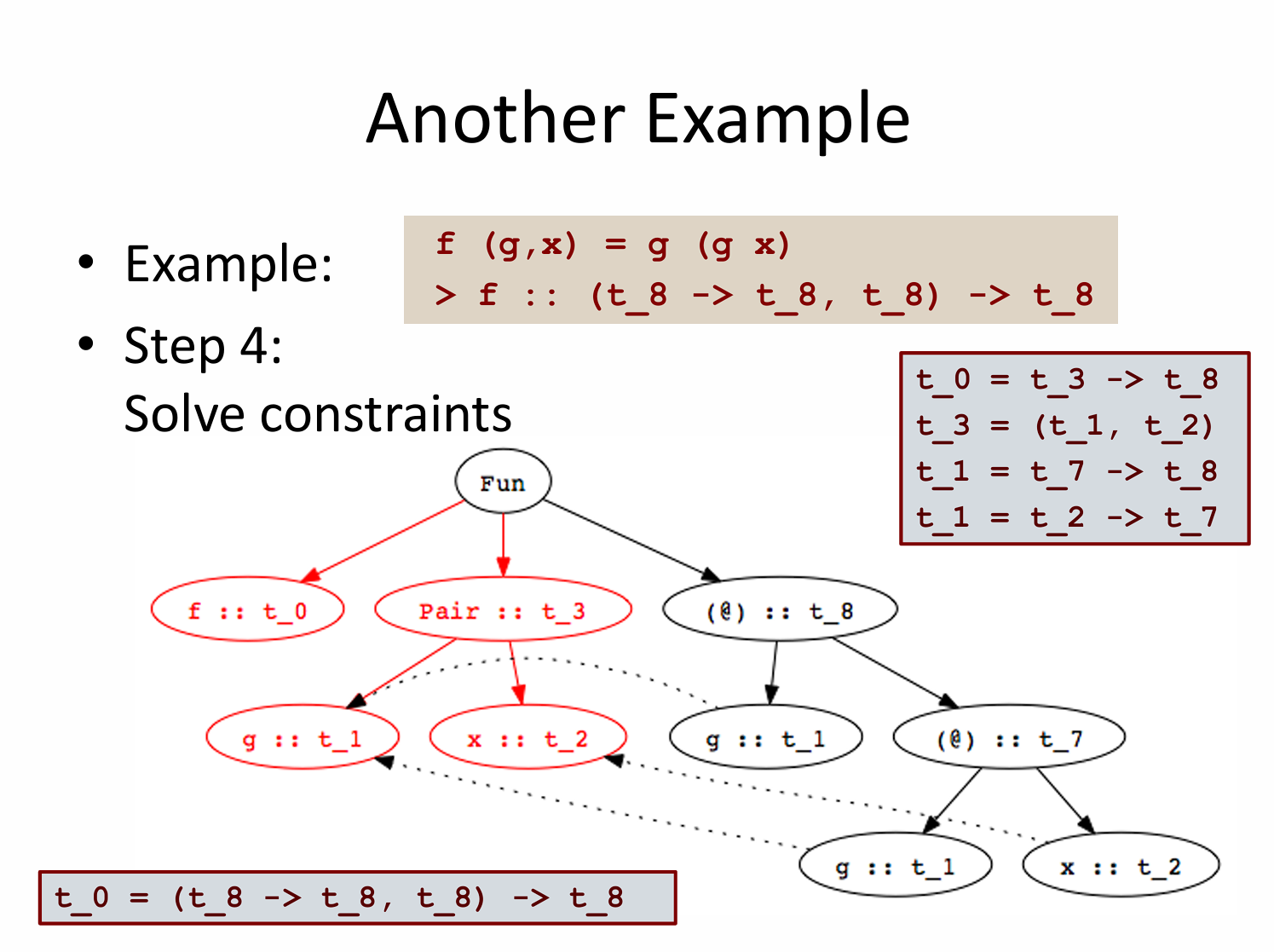
再来看看如下推断: f (g,x) = g (g x) 👇
- 合一原则
A -> B = C -> D=>A = C 且 B = D- 我们有
t_1 = t_7 -> t_8、t_1 = t_2 -> t_7 - 得到
t_7 = t_2、t_8 = t_7,即t_2 = t_7 = t_8
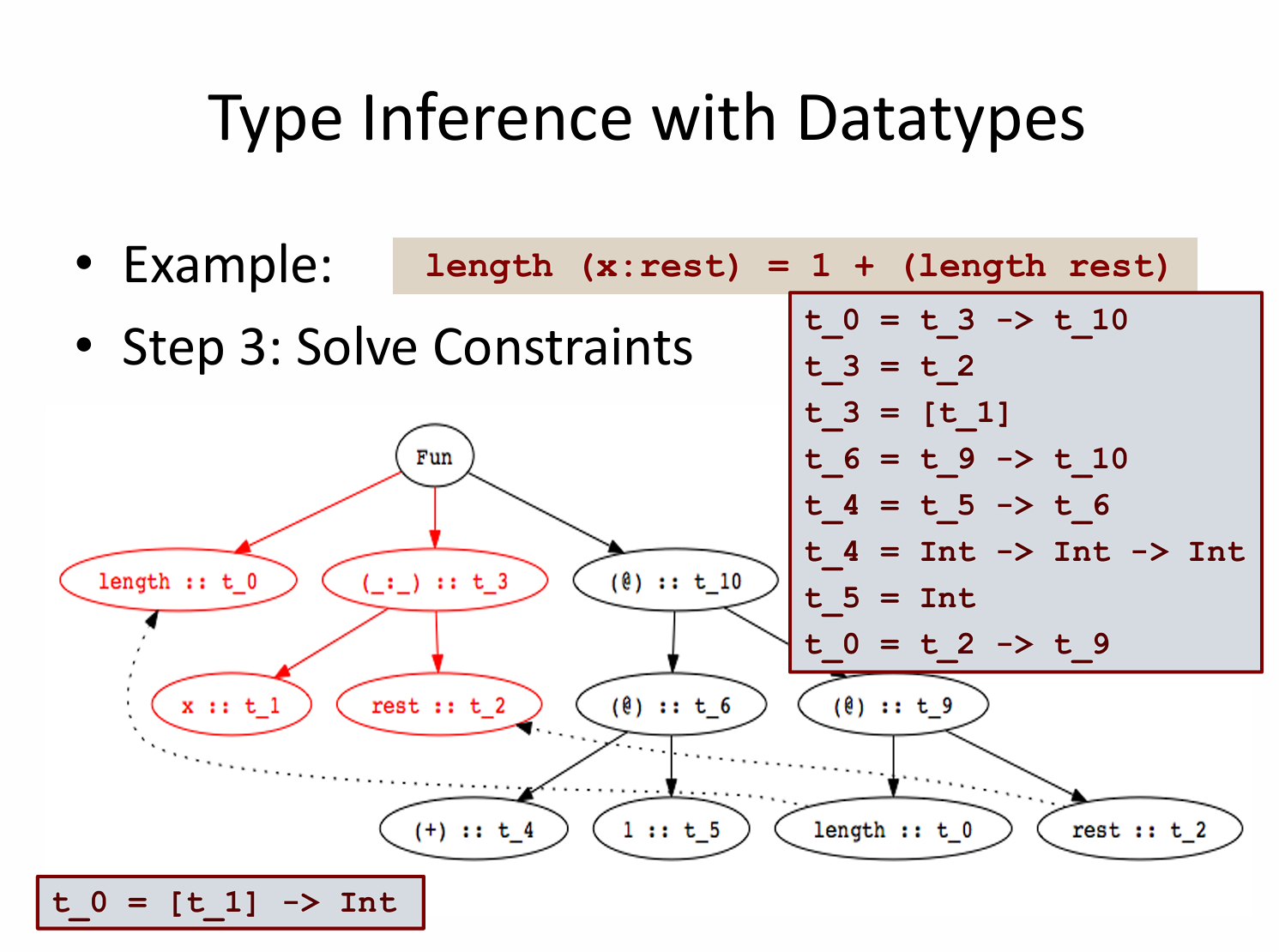
更抽象的例子: length (x:reset) = 1 + (length reset) 👇
-
(:)构造子(是一个普通函数)的类型:(:) :: a -> [a] -> [a] -
给我一个元素
a,再给我一个a的列表,我给你一个新的a的列表 -
这条类型规则是内建的、已知的,HM 推导可以直接用。
-
表达式
1 + length rest:这是一个二元函数应用- 第一个参数:
1 :: Int - 第二个参数:
length rest :: t_9 - 结果是
t_10 - 约束强制:
t_9 = Int、t_10 = Int
- 第一个参数:
-
表达式
1 + length rest:既然是二元函数应用,所以整个表达式的 AST 形态一定是1
2
3
4
5@
/ \
@ (length rest)
/ \
(+) 1- 然后再拆
length rest:这也是一次标准的函数应用
- 然后再拆
6. 面向对象编程
6.1 面向对象编程基础与历史 (06-OOP-1)
6.1.1 核心概念
-
对象:封装了
-
内部状态(state):实例变量 / 字段 / 成员变量 / 属性
-
对外操作(behavior):方法 / 成员函数
-
常见规则:内部状态通常是私有的(private),只能通过方法间接访问(封装)。
-
-
消息传递(Messaging):OOP 的本质是对象间通过发送消息进行交互。
x.add(y)可以看作向对象x发送add消息,参数为y- Alan Kay(Smalltalk 主要发明人)给 OOP 的定义重点是:
- only messaging(只有消息传递)
- state-process hiding(状态与过程隐藏)
- extreme late-binding(极致的晚绑定)。
- Alan Kay(Smalltalk 主要发明人)给 OOP 的定义重点是:
-
OOP 四大核心概念:
- 动态派遣(Dynamic Dispatch):运行时根据对象的实际类型决定调用哪个方法。
- 封装(Encapsulation):隐藏内部实现细节(private/public)。
- 多态(Polymorphism/Subtyping):子类型的对象可以被当作父类型使用。
- 继承(Inheritance):代码复用机制(注:现代观点中继承有较大争议,组合优于继承)。
6.1.2 语言演变历史
Simula 67 (OOP鼻祖)
- 起源:挪威计算中心,最初用于仿真。
- 贡献:引入了类(Class)、对象(Object)、继承 、虚方法、协程(Coroutine)、GC。
- 对象模型:对象被视为活动记录 (Activation Record)。
- 过程调用产生活动记录,通常调用结束即销毁。
- Simula的对象是“返回后仍保留”的活动记录(通过指针/引用访问)。
- 缺点:缺乏封装、
self/super、类成员变量(静态变量)、异常。
Simula 中的类与对象实现 🔥
- 类(class)= 返回其活动记录指针的函数(过程):
- 调用类(像调用函数):分配一个新的“活动记录”;
- 这个活动记录就是对象。
- 对象(object):可以看作“带有 Access Link 的活动记录”,Access link 用于访问外层环境(全局变量/静态数据)。
- “每次调用类之后产生的活动记录”;
- 内含字段(局部变量)、指向方法代码的指针等。
- 对象访问:
- 使用点运算符(dot notation):
o.var/o.proc(...)
- 使用点运算符(dot notation):
- 内存管理:
- 使用 垃圾收集(GC) 自动管理对象生命周期。
Smalltalk (纯OOP)
- 起源:Xerox PARC,Alan Kay主导,伴随Dynabook概念(现代笔记本/平板雏形)。
- 特点:
- 一切皆对象:连类本身也是对象(元类 Metaclass)
- 纯消息传递:所有计算都是向对象发送消息的过程
- 控制流结构(如if-else, loop)都是通过向Boolean或Block对象发送消息实现的。
- 动态类型:无编译期类型检查。
- 实现:
- 对象结构:类指针 + 实例变量。
- 方法查找:在类的方法字典中查找 -> 找不到则去父类找 -> 直到Object类 -> 报错(DoesNotUnderstand)。
6.2 C++ 与 Java 的对象模型 (06-OOP-2)
6.2.1 C++ 对象模型
- 设计目标:在C的基础上增加OOP特性,不牺牲效率(“Zero-overhead principle”:如果不使用某特性,就不应为此付费)。
- 内存布局:
- 对象像
struct一样在栈上或堆上分配。 - Vtable(虚函数表):属于 类 (Class),本质上是一个函数指针数组。每个包含虚函数的类,在编译期间都会生成一份唯一的 Vtable。
- Vptr(虚表指针):属于 对象 (Object),指向类的虚函数表(Vtable),表中存储了虚函数的地址。
- 对象像
- 方法调用:
- 非虚函数:编译期确定地址(静态绑定),效率等同C函数。
- 虚函数:运行时通过
vptr间接寻址(动态绑定)。代码:(*(p->vptr[0]))(p, args)。
- 多重继承(Multiple Inheritance):
- 问题:
- 命名冲突:两个父类有同名方法。解决:显式指定
A::f()。 - 菱形继承(Diamond Problem):D继承B和C,B和C都继承A。D中会有两份A的数据。
- 命名冲突:两个父类有同名方法。解决:显式指定
- 解决:虚继承(Virtual Inheritance)
class B : virtual public A。保证D中只有一份A,但引入了复杂的指针偏移计算,降低效率。
- 问题:
6.2.2 Java 对象模型
- 设计目标:简单、可靠、安全、可移植(Write Once, Run Anywhere)、简洁性与熟悉感(类似 C++)、效率(次要但考虑)
- 特点:几乎一切是对象;
- 所有对象都在**堆(Heap)**上分配,通过引用访问。
- 单继承:避免了C++多重继承的复杂性(特别是菱形问题)。
- 接口(Interface):实现多重类型的机制。一个类可以实现多个接口,但只继承一个实现。
- 没有
goto,没有运算符重载; - 静态类型检查 + 运行时检查 + GC。
- 垃圾回收(GC):解决了C++手动内存管理的安全性问题(悬垂指针、内存泄漏)。
- Finalizer:类似析构函数,但不保证立即执行(甚至不保证执行),主要用于释放非内存资源(如文件句柄)。
6.3 对象类型与子类型 (06-OOP-3)
6.3.1 子类型 (Subtyping) vs 继承 (Inheritance)
把对象看成“支持某些方法的实体”,这些方法集合就是对象的接口(interface),也就是对象的类型。
子类型定义:如果接口 A 包含 接口 B 的所有成员,那么 A 类型的对象在任何需要 B 类型对象的地方都可以用。
因此,Colored_point 是 Point 的子类型。
- 接口(Interface):对象的外部视图(能接收什么消息)。
- 实现(Implementation):对象的内部表示。
- 继承:实现的复用。
- 子类型:接口的兼容性(A是B的子类型
- 结论:继承
子类型与继承的关系
-
在 Smalltalk/JS 中:
-
继承(inheritance)是显式语言机制:用于代码复用;
-
子类型(subtyping)是一种“接口包含关系”:语言规范里没特意写,但系统设计中是默认假设。
-
-
在 C++ / Java 中:
-
通常约定:
- 类继承
class B : public A/class B extends A⇒ B 是 A 的子类型(public 继承,单继承)。
- 类继承
-
但要注意:
- 多继承、多态构造时,容易在“语义上不是好子类型”——即违反 Liskov 替换原则。
-
解释
“subtyping != inheritance”,给出反例🔥比如继承只为了复用代码但改变方法语义:
Rectangle/Square
Square为了复用Rectangle的代码而继承它,但通过重写setWidth/setHeight改变了这些方法的语义。- 对
Rectangle的使用者来说,setWidth只应改变宽度,不应影响高度;但Square违反了这一约定。- 所以在需要
Rectangle的地方,用Square替换可能破坏原来程序的不变式,不满足 LSP。- 于是,这里有继承,但没有合理的子类型关系,从而体现了 “subtyping != inheritance”。
6.3.2 子类型🔥
-
定义:如果 A 是 B 的子类型 (
-
宽度子类型(Width):子类型包含父类型的所有方法/字段,且可能更多。
-
深度子类型(Depth):字段类型也是子类型,如果字段类型是协变的(Covariant),通常是不安全的(针对可变数据)。
- 类型 A:
{ pet: Animal } - 类型 B:
{ pet: Cat } - 定义:如果
Cat是Animal的子类型,那么我们认为{ pet: Cat }也是{ pet: Animal }的子类型。这就是深度子类型。 - 可变数据:可读(安全);可写(不安全)
- 作为“读取者”:如果你要读取
pet,给你一个Cat没问题,因为Cat就是Animal。 - 作为“写入者”:如果你要写入(替换)
pet,你认为这是一个Animal容器,所以你可以往里面塞一只Dog。但在底层,这实际上是一个Cat容器!把狗塞进猫窝,类型就坏了。
- 作为“读取者”:如果你要读取
- 类型 A:
-
函数子类型:
-
参数是逆变(Contravariant):
-
返回值是协变(Covariant):
-
口诀:输入更宽容,输出更严格。
6.3.3 Java 数组的协变性 (Covariance)🔥
-
现象:在Java中,如果
Circle <: Shape,则Circle[] <: Shape[]。 -
问题:这是类型不安全的。(运行时可能写入非 Circle 对象抛出异常),但为了实用性(如
System.arraycopy)被允许。因此需要运行时检查,代价不小,语义也不“干净”.1
2
3
4Circle[] circles = new Circle[10];
Shape[] shapes = circles; // 编译期通过,允许(协变),因为 Circle[] <: Shape[]
shapes[0] = new Square(); // 编译通过,但运行时抛 ArrayStoreException -
原因:早期Java为了写通用的数组拷贝函数(如
System.arraycopy)而妥协。现代泛型(List<Circle>不是List<Shape>)修正了这个问题。
6.3.4 接口(Interface)与多重子类型
-
接口是“完全抽象的类”:
- 只声明方法,不包含实现(Java 8+ 支持
default方法,但 PPT 里作为“无实现的接口”来讲)
- 只声明方法,不包含实现(Java 8+ 支持
-
例:
1
2
3
4
5
6
7
8
9
10
11
12
13interface Shape {
public float center();
public void rotate(float degrees);
}
interface Drawable {
public void setColor(Color c);
public void draw();
}
class Circle implements Shape, Drawable {
// 必须实现两个接口中的所有方法
} -
接口可以多继承 / 多实现 → 构成子类型图而不是树;
-
解决/绕过 C++ 多继承的“钻石问题”:多继承的是“类型”,而不是“实现”。
-
代价:
- 接口方法的调用在 JVM 内部需要额外的查找(
invokeinterface):- 方法在类中的偏移量编译期不固定;
- 运行时查找后加缓存。
- 接口方法的调用在 JVM 内部需要额外的查找(
6.3.5 异常类型 (Exceptions)
1 | java.lang.Object |
-
Checked Exceptions 受检异常 (
Exception下除了RuntimeException及其子类之外的所有类):必须显式捕获或声明抛出。属于方法签名的一部分。- 强制检查。代码编译时,编译器会检查是否处理了该异常。
- 必须显式处理:要么用
try-catch捕获,要么在方法签名用throws声明。 - “可预见的意外”。通常由外部环境引起,程序应该预料到并有备选方案。
IOException(文件读写失败)、SQLException(数据库查询失败)、ClassNotFoundException
-
Unchecked Exceptions 非受检异常 (**
RuntimeException**及其子类, **Error**及其子类):无需显式处理。- 忽略。编译器不强制要求处理,编译能通过。
- 无需显式声明,也无需强制捕获(但可以捕获)。
- “程序员的逻辑错误”。通常是因为代码写错了,应该通过修改代码来修复,而不是捕获。
NullPointerException(空指针)、IndexOutOfBoundsException(数组越界)、OutOfMemoryError(严重错误)
6.4 Java 虚拟机与安全 (06-OOP-4)
6.4.1 JVM 架构
- Compiler:把 Java 源代码编译成字节码(
.class文件); - 类加载器(Class Loader):加载
.class文件。 - 验证器(Verifier) 🔥:安全的关键,在类被装载前,对字节码做静态检查
- 确保字节码安全(无栈溢出、无非法类型转换、跳转指令合法)。
- 数据流分析:确保变量在使用前已初始化(即便是跳转后)。
- Bytecode Interpreter / JIT Compiler:
- 逐条解释执行字节码。
- 运行时热点代码编译为本地机器码,提升性能。
6.4.2 方法调用指令(Method Lookup)
invokevirtual:调用类实例方法(根据对象实际类型动态查找,基于类 vtable,较快)。invokeinterface:调用接口方法(需要搜索,较慢,有 Inline Cache 优化)。invokestatic:静态方法(编译期确定)。invokespecial:构造函数、私有方法、super 调用。
“动态绑定”在 JVM 层面是通过不同的 invoke 字节码 + vtable / itable 查找实现的。
6.4.3 方法查找优化
- 内联缓存(Inline Caches, IC):
- 缓存上次调用的方法地址。
- Morphic(单态):缓存上一次调用的(类,方法地址)。如果下次调用对象类型相同,直接跳转。
- Polymorphic(多态 PIC):缓存多个(类,方法地址)对。遇到多种类型,生成类型判断树 (
if type==A jump targetA else ...)。
- OSR(On-Stack Replacement):在循环中进行解释执行到编译执行的切换。
6.4.4 Java 安全模型 (Sandbox / Stack Inspection)
- Security:防止未经授权使用计算资源。
- Java Security:防止粗心用户 / 恶意攻击者的输入。
-
沙箱模型(Sandboxing):限制代码对本地资源的访问:限制程序的加载器、验证器、解释器的功能。
-
类型安全:
- 强类型源语言 + 字节码;
- Verifier 保证字节码遵守类型规则
-
安全管理器(Security Manager):运行时权限检查(如文件读写、网络访问)。
-
栈检查(Stack Inspection):
- 权限检查不仅看当前方法,还看调用栈上的所有方法。
- 防止“特权代码”(如JDK库)被恶意代码调用去执行危险操作。恶意代码在栈上,会导致权限检查失败。
doPrivileged:允许受信任代码截断栈检查(即“我对此操作负责,不需检查我的调用者”)。
6.5 仓颉语言 OOP (06-OOP-5-Cangjie)
6.5.1 类型系统
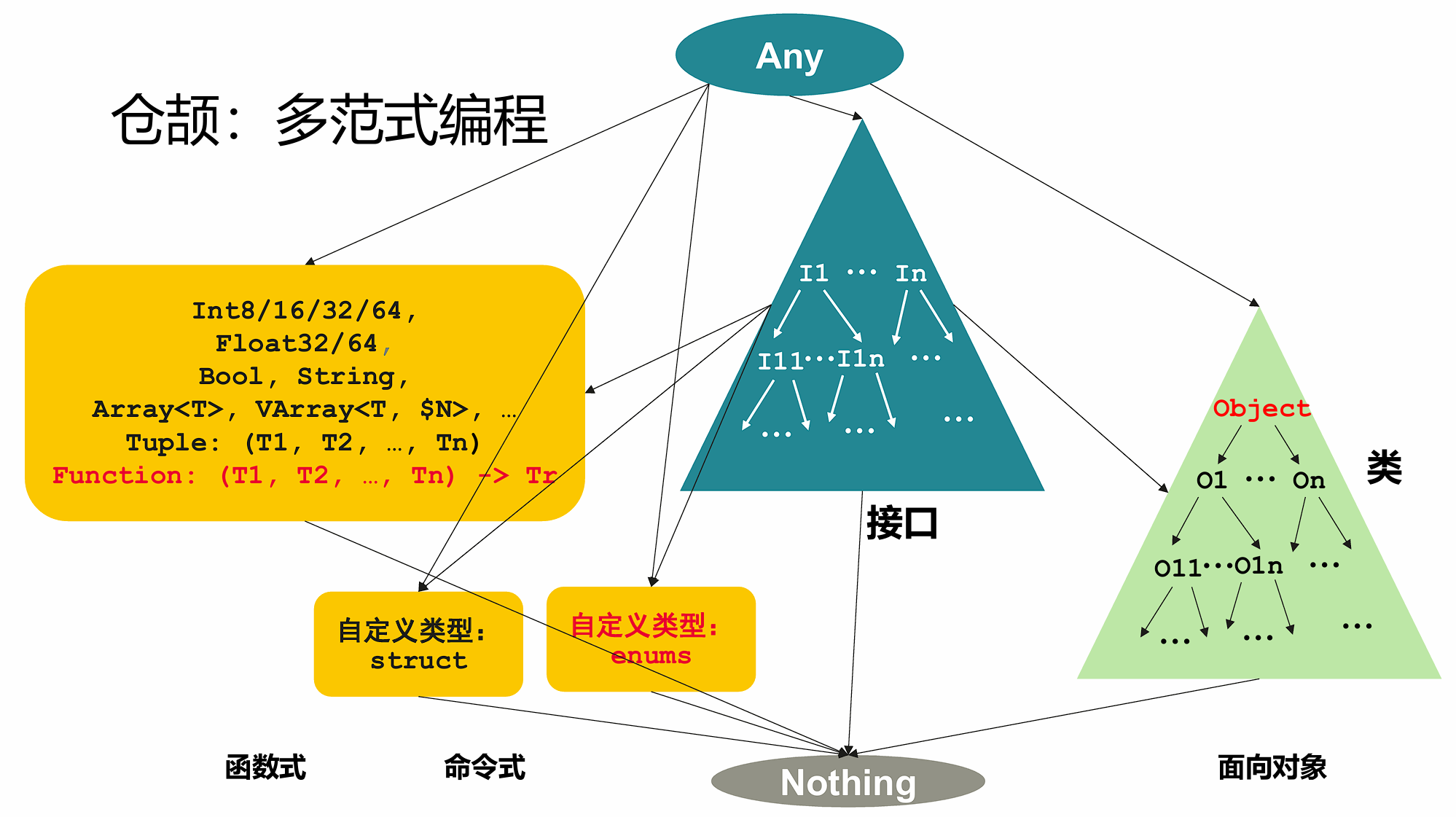
-
统一类型:所有类型(包括基础类型Int、Struct、Class)都是
Any的子类型。- 所有类型都是
Any的子类型 - 所有的 class 都是
Object的子类
- 所有类型都是
-
Struct vs Class:
-
struct:值类型(栈分配,Copy语义)。 -
class:引用类型(堆分配,Reference语义)。
-
6.5.2 类与接口
-
继承:单继承。默认类(类缺省)是不可继承的(类似 Java 中的 “final”)
-
只有
open修饰的类才可继承 -
只有
open修饰的方法才能被 override-
override关键字可以省略 -
Interface中的方法都是open的 -
动态派遣机制,open method 的调用采用动态派遣
-
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25open class Shape <: Equitable, ToString {
open func move(x: Int, y: Int): Unit {
print("Shape moved to ($x, $y)")
}
// Other common methods for shapes
}
class Circle <: Shape {
override func move(x: Int, y: Int): Unit {
print("Circle moved to ($x, $y)")
}
// Other common methods for circles
}
class Rectangle <: Shape {
override func move(x: Int, y: Int): Unit {
print("Rectangle moved to ($x, $y)")
}
// Other common methods for rectangles
}
let s1: Shape = Circle()
let s2: Shape = Rectangle()
s1.move(10, 20) // Should print "Circle moved to (10, 20)"
s2.move(30, 40) // Should print "Rectangle moved to (30, 40)" -
-
接口:支持多继承,可以包含默认实现(Default Implementation)
-
仅提供方法签名
-
但可以提供 default 实现
-
多继承问题:多个interface中对于同名函数, 有多个缺省实现 ——编译报错
-
-
Constructor:
- init函数,可以重载
- 调用顺序规定与Java类似
-
Finalizer:
-
~init
-
不允许this逃逸
1 | interface Comparable<T> { |
7. 模板与泛型 (07-Templates-and-Generics)
7.1 多态的对比
-
参数化多态 / 泛型(Parametric Polymorphism):
- 函数体对所有类型一视同仁(不依赖具体类型),类型只作为占位符。
- 例:
List<T>,swap<T>。- Java
generic <T> f(T x)或 Haskellf :: t -> t;
-
子类型多态(Subtype Polymorphism):
- 编译时只有一个函数体,通过动态派发处理不同子类。
- 基于继承关系(
- 例:
void f(Object x)可以接受String。
-
重载(Overloading):
- 同一个符号(如
+)指代不同的算法,取决于上下文类型。 - 这不是真正的多态,而是“特设多态 (Ad-hoc Polymorphism)”。
- 区别:
- 多态:一个算法适用于多种类型;
- 重载:同一名字关联多个不相关的算法,由上下文选择。
- 同一个符号(如
既然有子类型多态,为什么还要引入类型参数(泛型)?
- 泛型更适合表达“与具体类型无关,只要求一定接口(如比较、哈希)”的算法。
- 子类型多态通常要求把所有值包装成某个公共 superType,会丢失精确类型、需要强制转换。
7.2 C++ 模版 (Templates)🔥
7.2.1 机制与实现
- 编译期实例化(Compile-time Instantiation):
- 编译器根据使用的具体类型(如
Vector<int>,Vector<double>),生成该类型的专用代码副本。 - 异构实现:
vector<int>和vector<float>是完全不同的两个类,代码通过拷贝生成。 - 优点:
- 运行效率极高(零开销抽象)
- 支持特化:可以为特定类型(如
Vector<bool>)提供优化实现 - 支持元编程(Template Metaprogramming)
- 缺点:
- 代码膨胀 (Code Bloat)
- 编译时间长
- 编译错误信息晦涩
- 编译器根据使用的具体类型(如
Haskell 多态:
- 多态函数只编译为一个函数;
- 通过类型推导 + 字典传递(对于 type class)在调用点选择具体实现。
7.2.2 特化 (Specialization)
- 全特化(Full Specialization):为特定类型提供完全不同的实现。
- 例:
Set<char>可能用位图实现,而通用的Set<T>用树实现。
- 例:
- 偏特化(Partial Specialization):为一类类型提供特定实现。
- 例:
Set<T*>(针对所有指针类型)使用哈希表实现。
- 例:
7.2.3 模版元编程 (Template Metaprogramming)
- 利用模版实例化过程在编译期进行计算。
- 示例:编译期计算阶乘(通过递归模版实例化)。
- Policy-based Design:将策略(如内存分配策略、锁策略)作为模版参数传入类中,实现行为的组合(Mixin 风格)。
7.2.4 标准模版库 (STL)
- 核心组件:
- 容器(Container):
vector,list。 - 迭代器(Iterator):泛化的指针,连接容器与算法的桥梁。
- 算法(Algorithm):
sort,find,通过迭代器操作容器。
- 容器(Container):
- 优势:将算法与数据结构解耦 (Decoupling)。
7.3 Java 泛型 (Java Generics)🔥
7.3.1 机制与实现
- 类型擦除 (Type Erasure) 🔥:
- 同构实现:所有泛型实例在运行时共享同一份字节码。
- 编译过程:
- 编译期类型检查保证安全
- 生成字节码时,擦除类型参数:
List<T>->List,T->Object(或上界类型)。 - 在必要时插入强制类型转换 。
- 因此运行时不会保存泛型实参类型。
- 优点:
- 保持了旧版本 JVM 的兼容性
- 节省代码空间
- 缺点:
- 运行时丢失类型信息,无法区分
List<String>vsList<Integer>;- 无法
new T(),new T[],不能有static T field等。
- 无法
- 基本类型(
int)需要装箱 (Integer) 导致性能损耗。
- 运行时丢失类型信息,无法区分
7.3.2 通配符 (Wildcards)
?:任意类型。? extends T:上界通配符(协变),适合读取(生产者 Producer:只读不写)? super T:下界通配符(逆变),适合写入(消费者 Consumer:只写不读)- PECS 原则:Producer Extends, Consumer Super.
7.3.3 F-Bounded Polymorphism
- 定义:类型参数递归地出现在约束中。
- 典型场景:
interface Comparable<T> { int compareTo(T o); }- 约束写法:
<T extends Comparable<T>> - 含义:T 必须能和它自己进行比较。
- 约束写法:
7.3.4 协变与数组🔥
- Java 数组是协变的:
Integer <: Number所以Integer[] <: Number[]- 导致运行时错误:
nums[0] = 3.14, ArrayStoreException 问题
- 导致运行时错误:
- Java 泛型是不变的(Invariant):
List<Integer>不是List<Number>的子类。- 更安全,编译期报错。
7.4 C++ 模版 vs Java 泛型 (核心考点) 🔥
| 特性 | C++ Templates | Java Generics |
|---|---|---|
| 实例化方式 | 异构(Heterogeneous):每个类型生成一份独立代码。 | 同构(Homogeneous):类型擦除,共享一份代码。 |
| 执行阶段 | 编译期 / 链接期。 | 编译期检查,运行时无泛型信息。 |
| 基本类型支持 | 直接支持 (vector<int>)。 |
不支持,需装箱 (List<Integer>)。 |
| 特化 | 支持全特化和偏特化。 | 不支持特化。 |
| 代码大小 | 可能导致代码膨胀。 | 代码紧凑。 |
| 灵活性 | 极高(可用于元编程)。 | 较低(受限于类型擦除)。 |
8. 类型类 - Haskell(08-TypeClasses)
8.1 解决的问题
-
重载(Overloading) 的需求:有些函数不能对“所有类型”都工作,只能对支持某些操作的类型:
member :: [w] -> w -> Bool只对支持相等性比较的类型有意义;sort :: [w] -> [w]只对支持大小比较的类型有意义;serialize :: w -> String需要w可序列化;sumOfSquares :: [w] -> w需要w是“数值型”。
-
传统方案的缺陷:
- 传统的重载(Overloading)无法很好地处理多态函数(如
sort需要比较操作,print需要序列化操作)。 - 简单的参数化多态无法限制类型必须支持某些操作(如
a + b要求a是数字)。 - Ad-hoc 重载 (SML):仅支持内置类型,不可扩展。
- 完全多态 (Miranda):运行时检查,对不支持的类型抛异常(不安全)。
- 传统的重载(Overloading)无法很好地处理多态函数(如
-
Haskell 的方案:类型类(Type Class) —— 有原则的重载。
8.2 Haskell 的解决方案:Type Classes🔥
-
Type Class:定义一组操作(接口),类似 Java Interface,但更强大。
1
2class Eq a where
(==) :: a -> a -> Bool -
Instance:为具体类型实现这些操作。
1
2instance Eq Int where
x == y = intEq x y -
Qualified Types:在函数签名中添加约束。
1
member :: Eq a => a -> [a] -> Bool -- 读作:"对于任何支持 Eq 的类型 a,member 函数..."
8.3 实现原理:字典传递 (Dictionary Passing) 🔥
- 编译期翻译:编译器将 Type Class 转换为 字典 (Dictionary) 数据结构。
- 字典:本质上是一个包含函数指针的记录
struct。 - 带有约束的函数(如
square :: Num n => n -> n)会被编译成接收一个额外参数(字典d)的函数。 - 调用时,编译器根据具体类型自动传入对应的字典(如
dNumInt)。
- 字典:本质上是一个包含函数指针的记录
- 函数重写:
square :: Num n => n -> n- 被编译为:
square :: NumDict n -> n -> n - 即:函数多接收一个字典参数,通过字典调用具体的操作(如
+,*)。
- 实例生成:
instance Num Int会被编译为一个具体的字典值dNumInt。
8.4 高级特性
-
Constructor Classes:
-
Typy Class 的参数可以是类型构造器(如
List,Tree而不是List a)。 -
例:
Functor(即 PPT 中的HasMap)1
2class Functor f where
fmap :: (a -> b) -> f a -> f b- 这里
f是像List,Tree,Option这样的容器(类型构造器),而不是具体类型。 这允许map操作对各种容器通用
- 这里
-
map :: (a -> b) -> f a -> f b,其中f可以是[](List),Tree,Option。
-
-
Deriving:编译器自动生成常见 Type Class (
Eq,Show) 的实例代码。
9. IO Monad - Haskell(09-IO-Monad)
关键词:纯函数的美(equational reasoning) vs 现实世界的副作用(I/O、状态、异常、并发…);Haskell 通过 IO Monad 把“可观察的副作用”安全地组织起来,同时保留纯代码的语义与优化空间。
9.1 Beauty… and the Beast:为什么“直接加副作用”在惰性语言里行不通?🔥
-
Beauty(纯函数式的美):纯函数的语义就是数学函数,可以做等式推理(Equational reasoning):若
-
Beast(尴尬小队 Awkward Squad):语言要“有用”,就必须和外部环境交互。(副作用 = 除了返回值以外,对外部世界造成可观察变化,或依赖外部世界状态的行为)
- I/O:打印、读写文件、网络
- 状态更新:修改变量、数据结构
- 异常:抛错影响控制流
- 并发:线程调度带来的不确定性
- 外部库接口(FFI)
-
直接做法:像 ML/OCaml 这类严格求值语言,可以“按传统方式”加入:
putchar这类“函数”带 side effect;- 可赋值引用单元(
ref/:=/!); - 异常;
- 线程
-
但在惰性(lazy)语言中灾难发生:惰性语言里求值顺序刻意不定义,因此任何依赖求值顺序的 I/O/状态更新都不可靠:
print_char 'x'; print_char 'y';- 在纯函数里这成立,因为表达式只有 “值”
()。 - 在有副作用的语言里,“表达式的意义”不再只有返回值,还包含副作用
- 在纯函数里这成立,因为表达式只有 “值”
res = putchar 'x' + putchar 'y':输出顺序依赖(+ )的求值顺序;ls = [putchar 'x', putchar 'y']:如果只做length ls,由于length不会强制求值元素,可能什么都不打印。
-
课件提出的根本问题(Fundamental question)是:能否把纯 Haskell 作为基本范式,同时加上 imperative features,而不改变纯表达式的含义?
-
历史线索:90 年代早期出现了来自范畴论的“意外解法”——Monad(Moggi 的理论洞见,在 Haskell 中落地为 IO monad)。
-
IO Monad:Haskell 使用类型系统区分 纯代码 和 副作用代码。
9.2 在 Monad 之前【失败的尝试】:Streams / Continuations / World-Passing
9.2.1 Stream Model(Haskell 1.0 曾采用)与其问题 🔥
- 基本思想:把副作用“移到纯程序外”,让
main只做“请求/响应”流的变换。- 典型形式:
main :: [Response] -> [Request],其中Request/Response用代数数据类型枚举所有 I/O 事件。Request:我想让外部世界做什么(读字符、写字符、打开文件…)Response:外部世界做完后,把结果给我(读到的字符、写成功确认、文件句柄…)
- 惰性求值:程序可以在不处理任何响应的情况下**“先产出一堆请求”**
- 典型形式:
- Stream model 的主要缺点:
- 难扩展:新增 I/O 操作要改
Request/Response构造子,还要改外部 wrapper。 - 请求与响应不绑定:容易“out-of-step”,甚至导致死锁(deadlock)。
- 不可组合:两个
main很难像函数那样组合复用。 - 难以处理多个输入源:你必须在协议里“标记来源”,协议变得又大又笨重;响应到达的顺序不固定难控制。
- 难扩展:新增 I/O 操作要改
9.2.2 Continuations 与 World-Passing
- Continuations:通过把“下一步怎么处理结果”作为 continuation 传入 I/O 例程来组织流程(课件只点到为止,后续会讲)。
- World-Passing:把“世界状态”当作普通数据传递并更新;但早期设计者不知道如何保证对 world 的单线程访问,所以并不是严肃候选。
9.3 Monadic I/O 的关键想法:IO t 是“动作(action)”
- 关键定义:类型为
IO t的值是一个“动作”,执行时可能会产生某些副作用(如 I/O) 并最终返回一个类型为t的值 - 动作是一等值(Actions are first-class):动作可以当值传递/返回/放进数据结构;并且:
- 评估(evaluate)一个 action 没效果;
- 执行(perform)这个 action 才有副作用。
这句话非常重要:Haskell 仍然是“纯的”,因为纯代码只是在“构造 action”;真正的外部交互发生在运行时系统“执行 action”时。
9.3.1 基本原语
putChar :: Char -> IO ():打印字符,返回 Unit。getChar :: IO Char:读取字符,返回字符。return :: a -> IO a:不仅是返回。它的作用是将一个纯值a包装(wrap)进 IO Monad 中,不产生任何副作用。
9.4 最基础的 IO:getChar / putChar / main
- 课件给出的最小接口示例:
1 | getChar :: IO Char |
main :: IO ():一个完整的 Haskell 程序,本质上就是一个名为main的 IO action。
9.5 连接 actions:bind (>>=) 与 then (>>) 🔥
9.5.1 bind(>>=)的类型与直觉
- bind(读作“把前一个 action 的结果绑定给后一个 action”)类型是:
1 | (>>=) :: IO a -> (a -> IO b) -> IO b |
-
详细解释:
getChar >>= putChar实际是(>>=) getChar putChar-
(>>=)是一个函数,它接受两个参数:- 一个
IO a - 一个 函数:
a -> IO b
- 一个
-
返回一个
IO b
-
-
经典例子:读取一个字符再打印出来:
getChar >>= putChar等价于getChar >>= \c -> putChar c
1 | echo :: IO () |
以上都在课件中直接出现。
- bind 的执行语义(按课件的分解):
- 执行左边 action
a,得到结果r; - 把
r代入右边函数得到一个新 action; - 执行该 action 并返回其结果。
- 执行左边 action
9.5.2 then(>>):“不需要传值时”的顺序组合子
- 由于
putChar的返回值是(),很多时候我们只想“先做 m 再做 n”,不需要把m的结果传给n。
于是引入:
1 | (>>) :: IO a -> IO b -> IO b |
- 例子:把读到的字符打印两次(echoDup),以及做两次 echo(echoTwice):
9.6 return:把“纯值”提升为 action
- 关键点:我们有了
IO a这样的 action,但还经常需要把普通值塞回 IO 中。
return的作用是:不做任何 I/O,直接把值包装成一个 IO action。
1 | return :: a -> IO a |
- 例子:读取两个字符并返回二元组
(c1,c2)。注意(c1,c2)只是普通值,但我们要返回的是IO (Char,Char):
1 | getTwoChars :: IO (Char,Char) |
9.7 do-notation:把 monadic 代码写得像命令式 🔥
9.7.1 do 写法 vs “原生” >>= 写法
课件给了完全对应的两个版本:
1 | -- Do Notation |
9.7.2 do 的去糖规则
- do 只是语法糖,核心规则如下:(
e是单个表达式,es是多条语句)do { e } = edo { x <- e; es } = e >>= \x -> do { es }do { e; es } = e >> do { es }do { let ds; es } = let ds in do { es }
- 细节:
- generator 绑定的变量作用域是后续的 do 片段;
- do 的最后一项必须是表达式(不是绑定语句)。
- 缩进版与分号版等价:若省略分号,生成器必须对齐,缩进替代标点。
9.7.3 Bigger example:用递归写 getLine
课件示例强调了:纯代码(if/递归)可以和 monadic 操作混在一起,并且可以嵌套 do:
1 | getLine :: IO [Char] |
9.10 First-class actions:自定义控制结构(control structures)🔥
因为
IO Action是一等值,所以我们可以把“循环/for/sequence”等控制结构写成普通函数——这点是 Haskell IO 非常强的地方。
-
mapM:先 map 生成动作列表,再 sequence。mapM_:忽略返回值
1 | mapM :: (a -> IO b) -> [a] -> IO [b] |
for(把列表当循环变量):
1 | for :: [a] -> (a -> IO b) -> IO () |
sequence:执行列表中的一系列动作。把一串 IO actions 变成“执行所有动作并返回结果列表”的大 action:sequence_:执行一系列动作,忽略返回值。
1 | sequence :: [IO a] -> IO [a] |
forever / repeatN:
1 | forever :: IO () -> IO () |
- First-class actions 让程序员可以写“应用特定”的控制结构。
9.11 IO 提供的世界交互:文件 I/O(类比 C 标准库)
- 课件列举的文件操作接口(和 C 的
fopen/fputs/fgets/fclose很像):
1 | openFile :: FilePath -> IOMode -> IO Handle |
9.12 IORef:在 IO 里做“可变引用”(imperative state)🔥
9.12.1 IORef 的抽象接口
IORef a:一个可变单元(mutable cell),存放类型为a的值;其本身是抽象类型。
1 | data IORef a -- Abstract type |
9.12.2 例子 1:用 IORef 计算 1…n 的和(“能写但不该写”)
课件给了一个完全命令式的写法(可作为“理解 IORef 与 do 的综合题”):
1 | import Data.IORef |
-
课件吐槽:这很糟糕;它看起来需要副作用,但其实用纯代码
sum [1..n]就够了。考试里经常会借这个点问你:什么时候该用 IORef(确有外部可变状态需求),什么时候不该(纯可计算)。
9.12.3 例子 2:给文件句柄“附带计数器”
这个例子更合理:在输出时顺便统计写出的字符数,适合用引用。
1 | type HandleC = (Handle, IORef Int) |
9.13 IO Monad 作为 ADT:为什么“进去了就出不来”?
- 课件观点:所有 I/O 原语都会返回一个 IO action,但只有 bind (>>=) 会把 IO action 当参数;而 bind 是唯一能组合 actions 的方式,因此强制顺序性(sequentiality)。
- “在程序内部没有出路”:你不能写一个
IO String -> String这种“逃逸函数”,否则纯/非纯的边界就被打破。
9.14 Irksome Restriction & unsafePerformIO:最后的“后门”与代价
9.14.1 为什么 readFile 的结果是 IO String?
- 你直觉上可能想写:
1 | configFileContents = lines (readFile "config") -- WRONG! |
但 readFile 返回 IO String 而不是 String,因此这不通过类型检查。
- 课件给了两种“看似方案”的对比:
- 把整个程序都写在 IO 里(会损失纯代码简洁性);
- 试图定义
IO String -> String的逃逸函数(这正是被禁止的)。
9.14.2 unsafePerformIO:类型不安全的原语(非常危险)
- Haskell 实现通常提供一个“最后的后门”:
1 | unsafePerformIO :: IO a -> a |
- 使用它的“证明义务(proof obligation)”:你要向编译器保证这个 I/O 的时机相对其他操作无关紧要。课件也强调:名字刻意起得很长就是为了吓退你。
- 它会破坏类型系统的健全性(soundness):所以“Haskell 类型安全”只对不使用
unsafePerformIO的程序成立。 - 课件给了一个经典“炸类型系统”的例子:构造一个带
forall a的“多态引用”,再用它实现“任意类型转换(cast)”。
9.15 GHC 的实现直觉:world-passing semantics(保持纯语义,同时高效执行)🔥
- GHC 用 world-passing 语义解释 IO:
- 用一个不可伪造(unforgeable)的
Worldtoken 表示世界; - 把
IO t表示成函数:
- 用一个不可伪造(unforgeable)的
1 | type IO t = World -> (t, World) |
并据此实现 return 与 (>>=):
1 | return :: a -> IO a |
- 关键保证:由于输出 world 依赖输入 world,类型强制 world 单线程传递,因此得到的代码仍是单线程(single-threaded)。
- 最后代码生成器把“传 world”优化成就地更新(in-place),因此效率可以接近命令式实现。
9.16 IO Monad 为什么是 Monad?Monad 的定义与示例
9.16.1 Monad 的组成(抽象层)
- 课件给出的 monad 抽象:
- 类型构造子
M bind :: M a -> (a -> M b) -> M breturn :: a -> M a- 以及它们必须满足的定律(laws)。
- 类型构造子
9.16.2 课件列举的 monad 例子(帮助理解“把计算放进 M(A)”)
课件举例说明:你可以写“对 A 的计算”,但用 M(A) 的方式来运行它:
- 错误处理:
M(A) = A ∪ {error}(类似Either/Maybe) - 信息流追踪:
M(A) = A × Labels - 非终止:
M(A) = A ∪ {∞} - 状态:
M(A) = A × States(这和 IO 的 world-passing 直觉非常接近)
9.17 Monad Laws 与等式推理(Reasoning)🔥
9.17.1 Monad Laws(至少要会写出前三条)
课件列出的核心定律:
-
左单位元(left identity):
return x >>= f = f x- 你把一个“纯值 x”用
return包成一个动作, 然后立刻用(>>=)把它交给f,那还不如直接调用f x - 这是“
return不引入额外行为”的保证。
- 你把一个“纯值 x”用
-
右单位元(right identity):
m >>= return = m-
m :: IO a,(>>=) :: IO a -> (a -> IO b) -> IO b,return :: a -> IO a- 所以这里
b = a,m >>= return :: IO a
- 所以这里
-
你执行一个动作
m,然后只是把它的结果用return包回去,那整个过程跟 只执行m是一样的 -
这是“
return不改变已有动作”的保证。
-
-
结合律(associativity):对应 do 结构的重排。
(m >>= f) >>= g = m >>= (\x -> f x >>= g)- 把一串 IO 动作“先这样分组”还是“那样分组”, 执行顺序和结果不变。
9.17.2 (>>) 与 done 的派生定律
-
课件定义 + Monad Laws 的推论:
done :: IO () = return (),m >> n = m >>= (\_ -> n) -
因此可以推出:
done >> m = m、m >> done = m、m1 >> (m2 >> m3) = (m1 >> m2) >> m3。1
2
3
4
5done >> m
= return () >>= (\_ -> m)
= (\_ -> m) () -- 根据左单位元:return x >>= f = f x
= m1
2
3
4m >> done
= m >>= (\_ -> return ()) -- m >>= return = m,就是“忽略结果,原样 return”
= m -- 根据右单位元:m >>= return = m1
2
3
4(m1 >> m2) >> m3
= m1 >>= (\_ -> m2 >>= (\_ -> m3)) -- 根据结合律:(m >>= f) >>= g = m >>= (\x -> f x >>= g)
= m1 >> (m2 >> m3)
9.17.3 用 equational reasoning 证明程序性质:putStr 例子
- 定义:
1 | putStr :: String -> IO () |
- 命题(Proposition):
putStr r >> putStr s = putStr (r ++ s) - 证明思路:对
r归纳。
证明思路
因为 putStr 是 按 r 的结构递归定义的。
所以证明也要按同样结构来:
- Base case:
r = [] - Inductive step:
r = c:cs
1️⃣ Base case:r = []
左边:
1 | putStr [] >> putStr s |
用定义:
1 | = done >> putStr s |
用 (>>) 的单位元定律:
1 | = putStr s |
右边:
1 | putStr ([] ++ s) |
左右相等 ✔
2️⃣ Inductive step(完整“等式走法”)
假设归纳假设成立:
1 | putStr cs >> putStr s = putStr (cs ++ s) |
证明:
1 | putStr (c:cs) >> putStr s |
展开定义:
1 | = (putChar c >> putStr cs) >> putStr s |
用 (>>) 的结合律:
1 | = putChar c >> (putStr cs >> putStr s) |
用归纳假设:
1 | = putChar c >> putStr (cs ++ s) |
再用 putStr 的定义反向合并:
1 | = putStr (c : (cs ++ s)) |
而:
1 | c : (cs ++ s) = (c:cs) ++ s |
所以:
1 | = putStr ((c:cs) ++ s) |
✔ 证明完成。
10. Garbage Collection(垃圾回收基础知识)(10-GarbageCollection)
10.1 什么是垃圾回收?为什么需要?(概念与意义)
10.1.1 基本内存操作 & managed vs unmanaged
- 程序的基本内存操作(最朴素视角):
- 分配(allocate):为新对象/新数据申请空间(如
new/malloc) - 写(write):写字段/写数组/写指针/写引用
- 读(read):读字段/读数组/读指针/读引用
- 释放(free):把不再需要的空间归还给系统(
free/delete)
- 分配(allocate):为新对象/新数据申请空间(如
- managed language(托管语言):Cangjie / Java / Go / Swift 等
- 语言/运行时负责“什么时候释放”,程序员不直接
free
- 语言/运行时负责“什么时候释放”,程序员不直接
- unmanaged language(非托管语言):C / C++ / Rust 等
- C/C++:程序员显式释放(或靠 RAII/智能指针等)
- Rust:靠类型系统静态检查资源生命周期(本章后面会讲)
垃圾回收(GC)解决的核心问题是:“内存如何释放?”
但要想“高效正确地释放”,GC 也会影响分配、写、读等路径(例如写屏障/读屏障)。
10.1.2 为什么使用垃圾回收?(优势与动机)🔥
- 避免常见内存错误
- 内存泄漏(memory leak / 无用单元):对象已经不可达/不可用,但没释放 → 内存不断增长
- 悬垂引用(dangling reference):对象已释放但仍可访问 → 崩溃/未定义行为(C/C++ 高频灾难)
- 责任分离
- 程序员把注意力放在业务逻辑,而不是手动管理生命周期
- 性能可能更好(反直觉但很常见)
- 某些 GC 体系下的分配是 bump-pointer:只要移动指针即可,极快、cache 友好
- 运行时/编译器可生成 fast path(多数情况走内联快路径)
- 更利于并发/多核
- 即使应用单线程,也可以用多个 GC 线程并行做回收工作
- 可以把 GC 线程调度在小核(big.LITTLE)以降低能耗
- 一些无锁结构在 GC 存在时更容易实现(如某些 RCU / lock-free queue 模式)
10.2 垃圾回收的基本原理:堆、根、可达性(Reachability)
10.2.1 基本概念(必须背熟)🔥
- 堆(heap):用于分配对象的区域,由 GC 管理
- 对象(object):在堆上分配的一块存储空间
- 引用(reference):指向对象的指针(可能是压缩指针/句柄等实现)
- 根(root):从“堆外”指向“堆内对象”的引用
判定垃圾的核心:从根集合出发不可达(unreachable)的对象就是垃圾。
10.2.2 引用关系与可达性图(Reachability Graph)🔥
- 任何一次“写引用变量/写引用字段”都会改变对象图(object graph):
var r1 = C0():写一个根引用(全局/局部变量)obj1.r2 = C0():写对象字段(边obj1 -> newObj)
- 所有引用关系构成一张有向图:根集合是图的起点
- 活对象(live):从根出发可达
- 垃圾对象(garbage):从根出发不可达
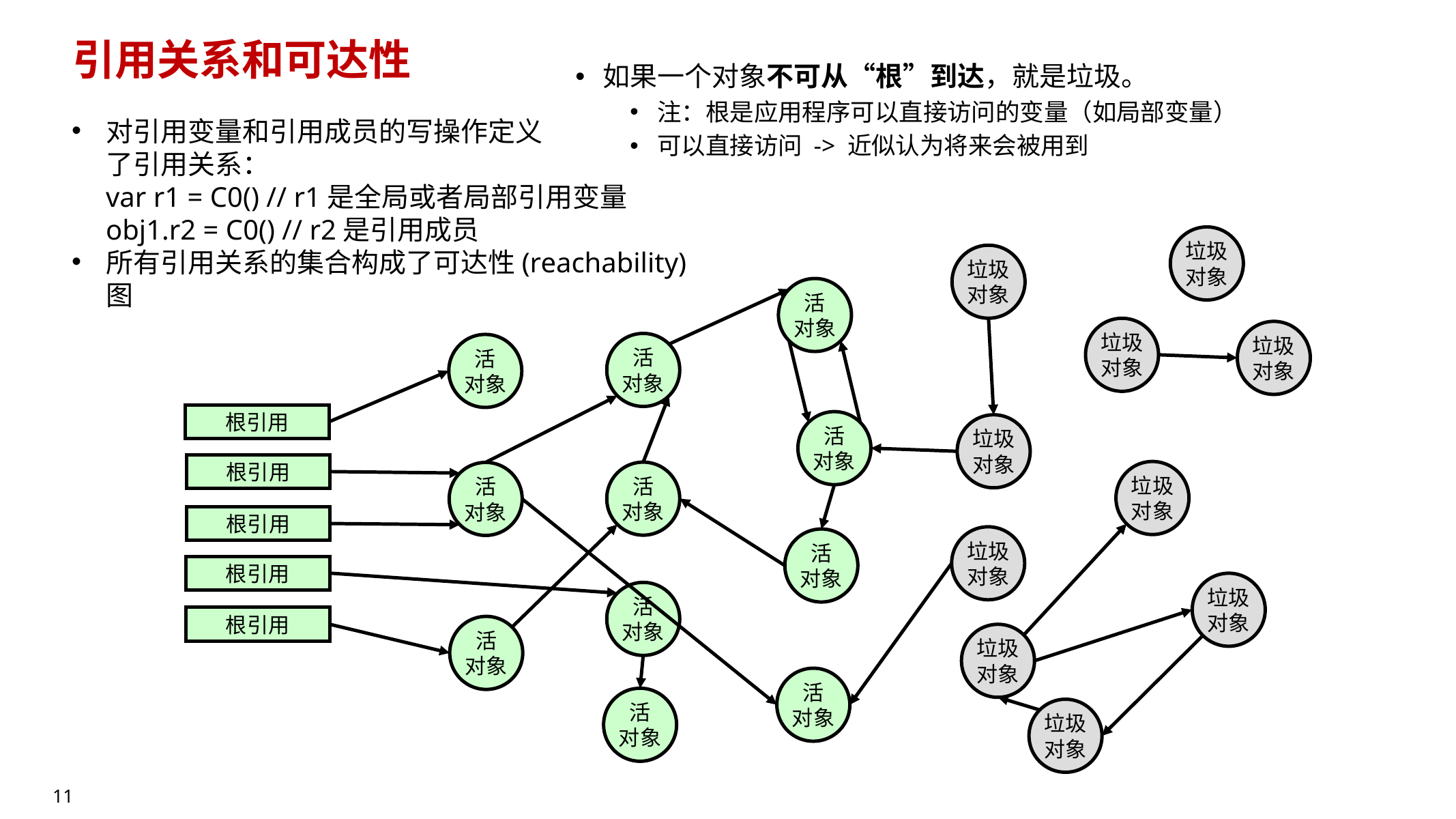
近似理解:根集合里可直接访问的变量“将来可能会用到”,所以从根可达的都先认为是活的。
10.2.3 根集合(Root Set)包含哪些?🔥
根集合中的引用由语言/VM/运行环境定义,典型包括:
- 局部变量(栈上或寄存器中)
- 静态(全局)变量
- 外部接口保留的引用:例如 JNI 的
LocalRef/GlobalRef - 其他 VM 级根:线程对象、类元数据、运行时结构中的指针等(不同 VM 定义不同)
重点:GC 首先要正确找到“根引用”。这就是为什么后面必须引入 Stack Map。
10.2.4 对象布局(Object Layout)与“引用字段识别”🔥
对象通常包含:
- 对象头(header):与 GC 相关的元数据(mark word、转发表信息、typeinfo 指针…)以及语言相关元数据
- 字段(fields):
- 值字段(value fields):整数/浮点等非引用
- 引用字段(reference fields):指向其他对象
GC 必须知道:对象里哪些位置是“引用”。
运行时之所以能识别引用字段,靠的是编译器/VM 提供的 Object Map(后面 10.6)。
10.3 垃圾回收算法的三大组成部分(分配 / 识别 / 回收)🔥
任何具体 GC 算法都可以视为三件事的组合:
- 内存分配(allocation):给新对象找空间
- 垃圾识别(garbage identification):识别哪些对象是垃圾
- 内存回收(reclamation):把垃圾占用的空间回收以供再分配
不同 GC(mark-sweep / mark-compact / copying / region-based / generational / concurrent…)本质上是三件事的不同组合与工程化增强。
10.4 内存分配(Allocation)
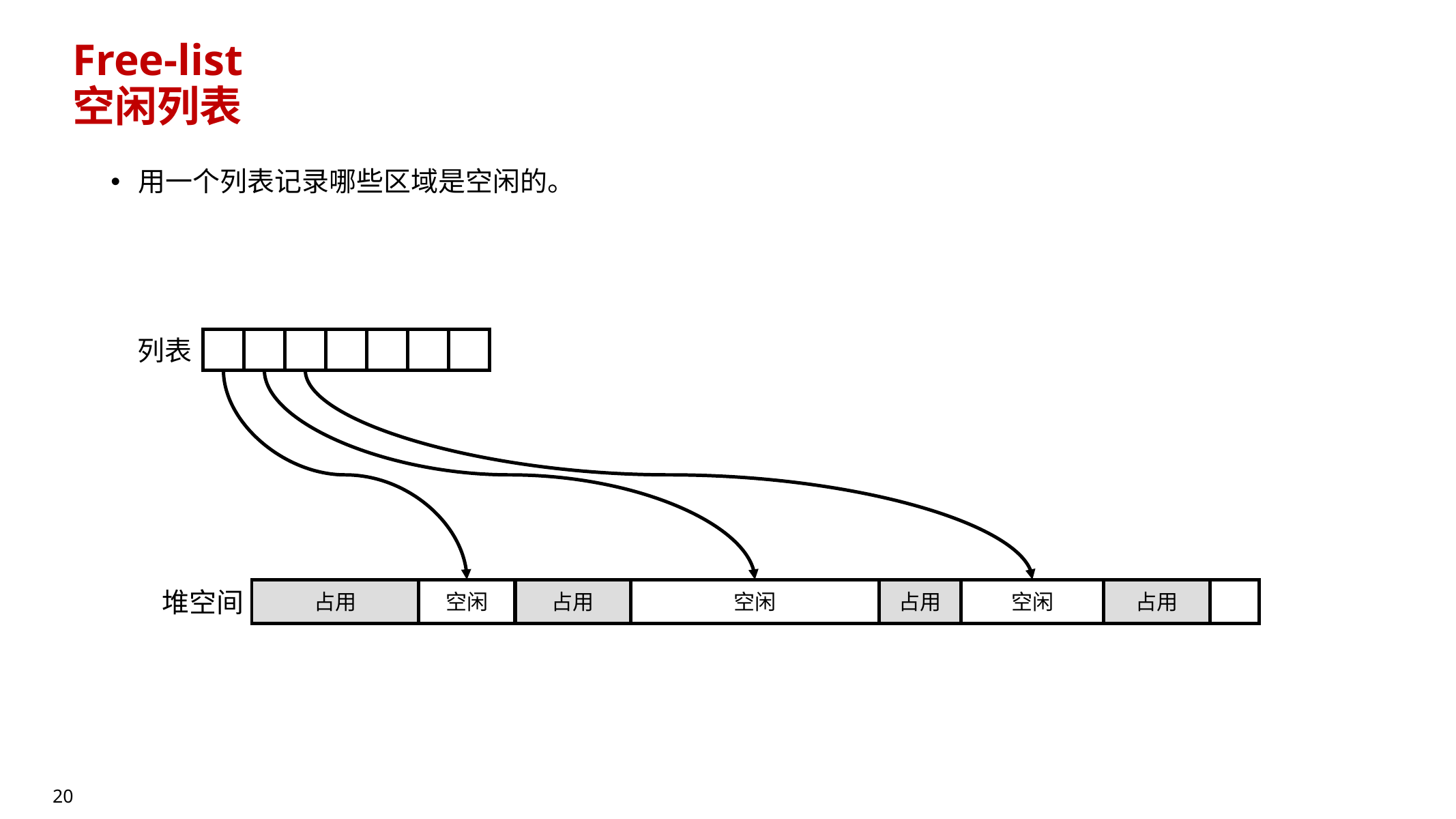
10.4.1 Free-list(空闲列表)分配
- 维护一个列表记录哪些区域空闲
- 分配时:在 free-list 中找合适大小块(可能需要分裂/合并)
- 常见工程优化:Segregated Free-list(按大小分桶管理)
- 提高速度、一定程度缓解碎片,但无法根治碎片
10.4.2 Bump-pointer(顺序/连续分配)
- 也常被称为:bump-a-pointer / contiguous allocation(连续分配);有时译作“阶跃指针”。
- 空闲空间保持连续,分配时只需移动
free_pointer(“bump”一下) - 优点:操作简单,cache 局部性好,通常比 free-list 更快
- 缺点:依赖“空闲空间连续”这一性质,因此常与 copying/evacuation 或 compaction 搭配
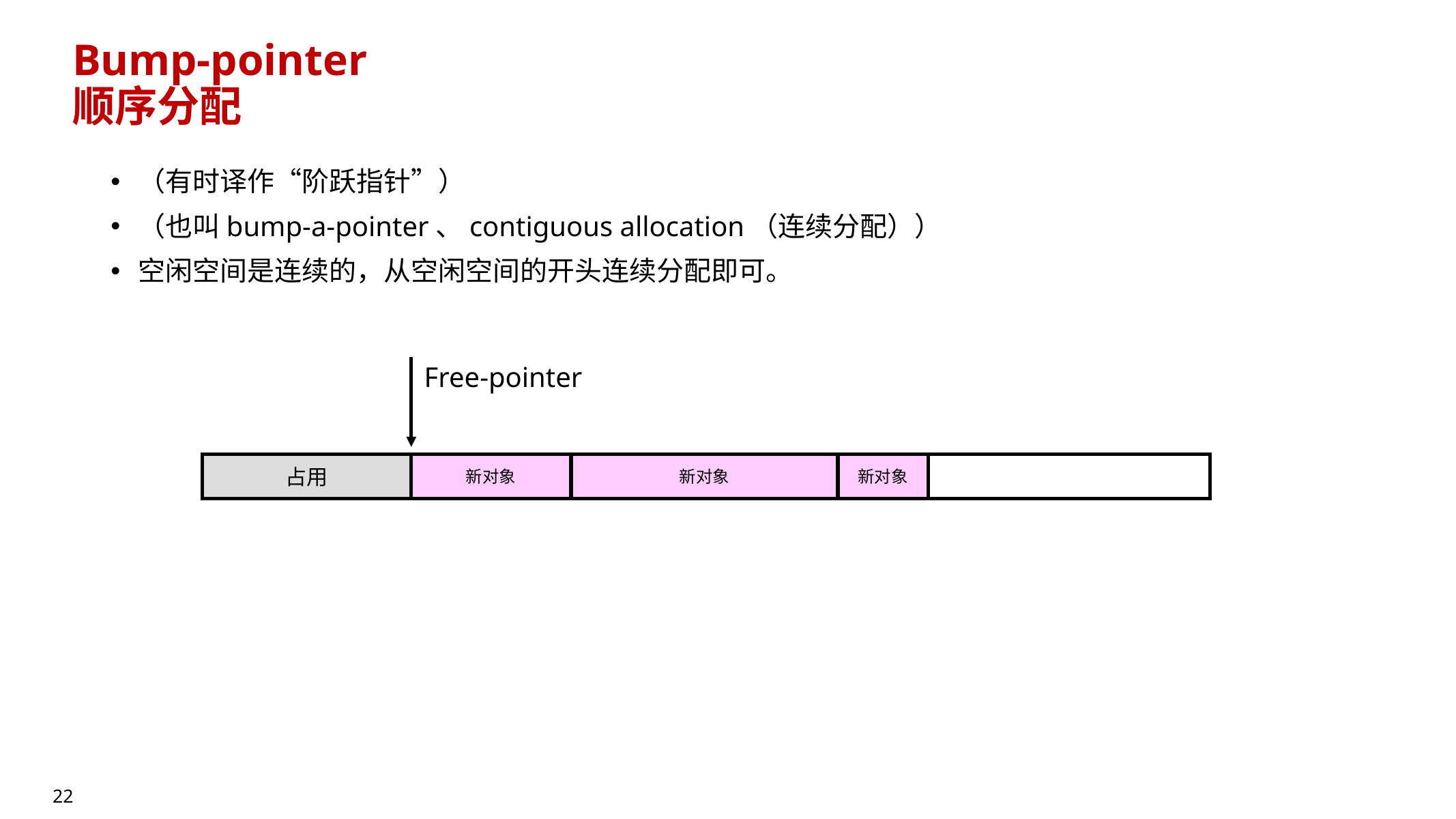
10.4.3 Region-based(分块/分区)分配(综合型)
- 把堆分成等大的大块(chunk/region,例如 32KiB+)
- 块内用 bump-pointer 分配;对象不跨块
- 回收时:完全空的块可以整块回到块 free-list
- 如有必要可通过拷贝/整理做碎片整理(defragmentation)
Region-based 思想是现代很多 GC 的基础(例如 G1 的 region 视角)。
10.5 垃圾识别(Garbage Identification)
10.5.1 Tracing(跟踪/可达性分析)🔥
- 从根集合出发遍历对象图,计算“传递闭包(transitive closure)”
- 可达 = 活对象;不可达 = 垃圾
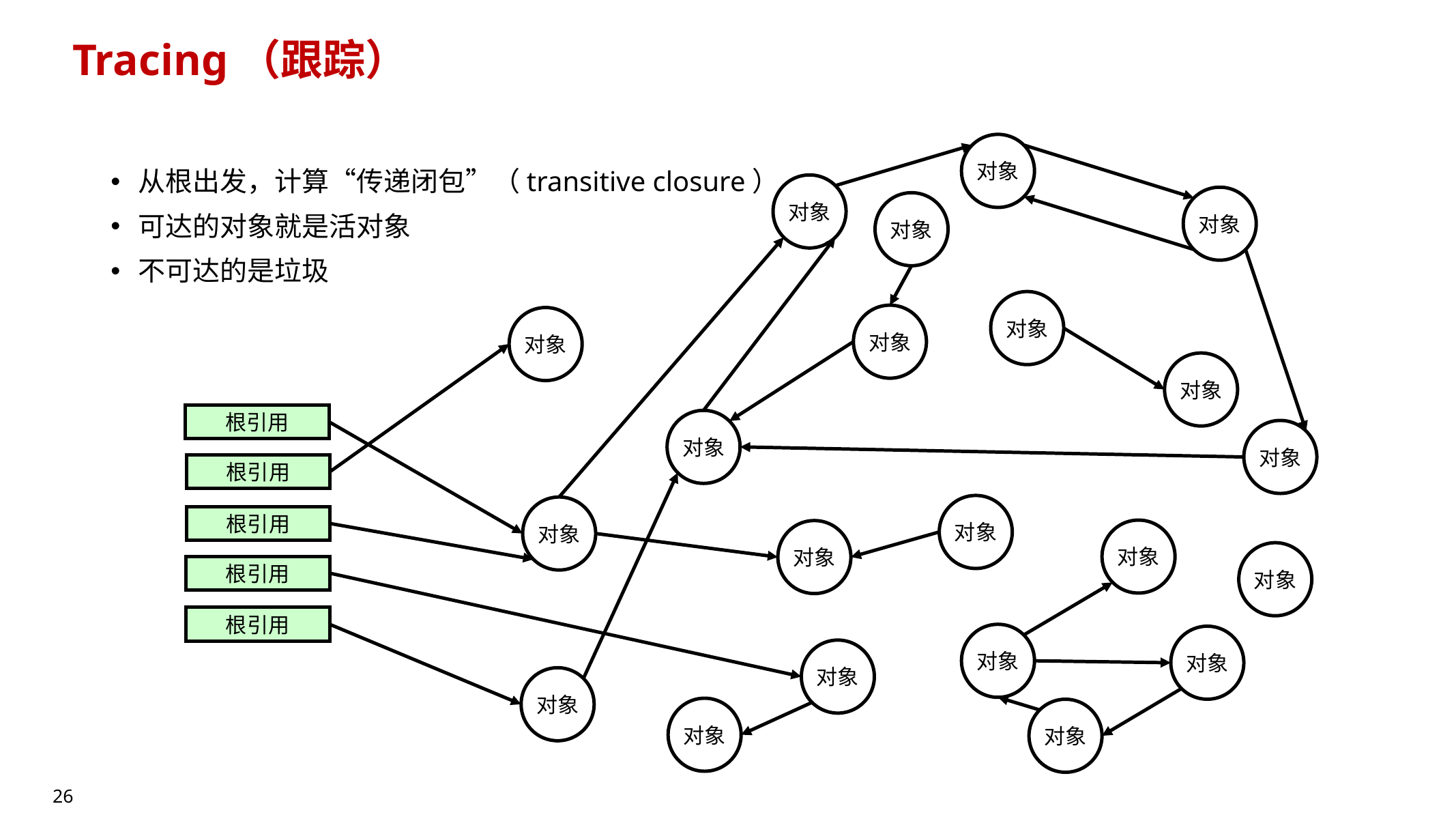
特点:
- 能正确处理环(cycle)——因为可达性与环无关
- 代价:若每次都全堆 tracing,会扫描大量“其实还活着/大概率还活着”的对象 → 成本高
→ 解决思路:分代 GC(10.5.3)
10.5.2 Reference Counting(引用计数,RC)🔥
- 每个对象维护引用计数 RC:有多少个引用指向它
- 当 RC 降到 0 时,它必然不可从根到达 → 必然是垃圾(可立即回收)
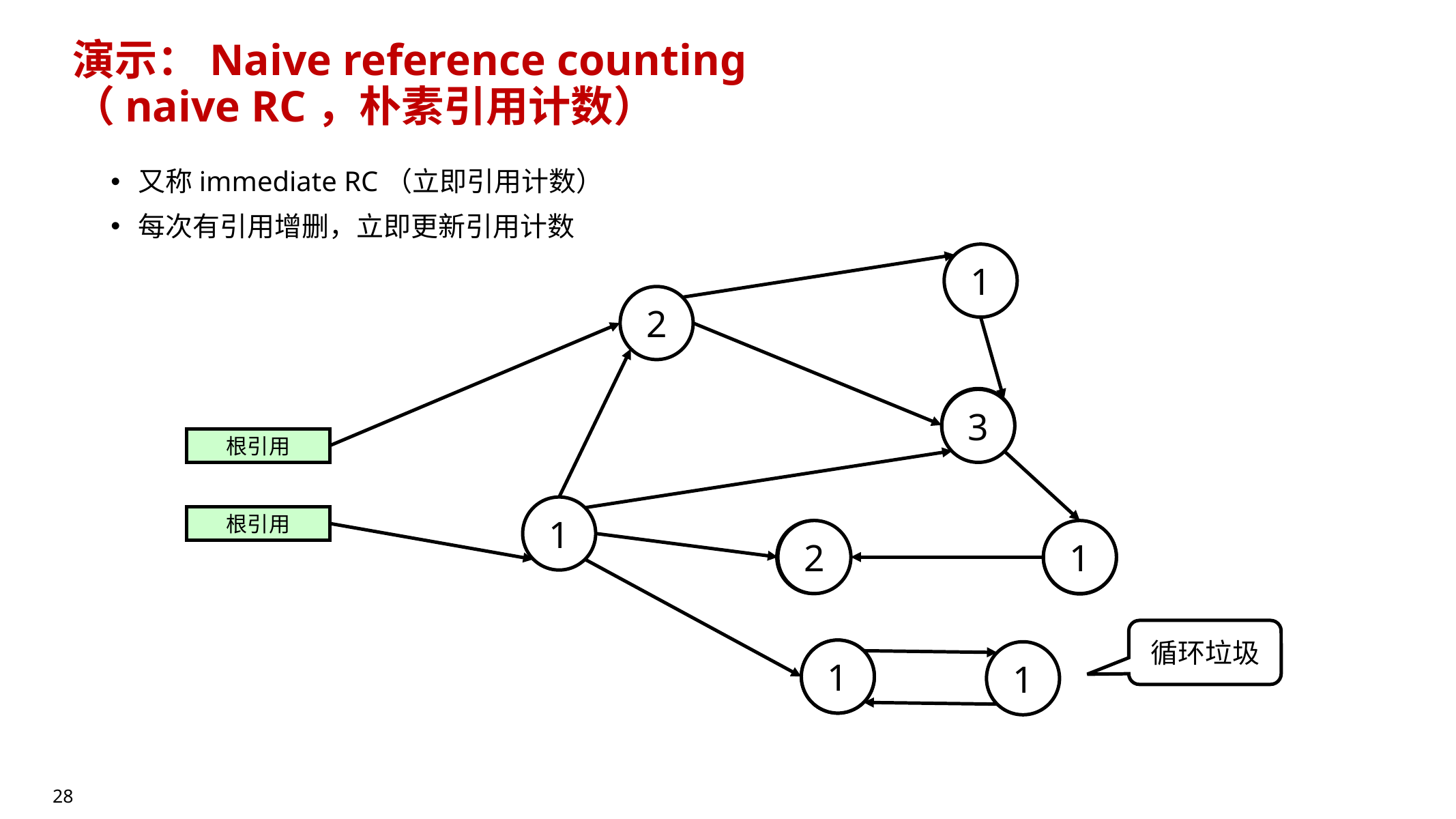
问题与对比:
- 致命缺陷:无法识别环形垃圾(cycle garbage)
- 两个对象互相引用,RC 都不为 0,但从根不可达 → 泄漏
- 工程上常用:用 tracing 做 backup tracing 补齐 RC 的环;
- 也有人用 trial deletion 等检测环,但课件提醒:trial deletion 通常很慢,不建议作为主方案。
- RC 的“及时”回收 ≠ 不卡顿:
- 回收一个很深的链表可能导致同步递归释放 → 仍可能长暂停
- tracing 的 stop-the-world 也会造成暂停
→ 进一步需要 并发 GC(10.6)
10.5.3 “及时” vs “不卡顿”:延迟(latency)问题🔥
- 及时:尽早发现垃圾并释放,避免内存耗尽
- 不卡顿:应用线程是否被 stop-the-world(STW)暂停,能否响应请求
- STW tracing 可能导致卡顿
- RC 同步回收巨大结构也可能卡顿
- 解决路径:
- 用 分代 GC 缓解 tracing 的“全堆扫描”
- 用 并发 GC 降低/消除 STW
10.6 内存回收(Reclamation):清扫 / 压缩 / 撤离(Copy)
10.6.1 Sweeping(清扫到 free-list)
- 垃圾对象占用的空间直接加入 free-list
- 优点:回收速度快(不需要搬移活对象)
- 缺点:容易产生碎片(fragmentation),大对象可能无法分配
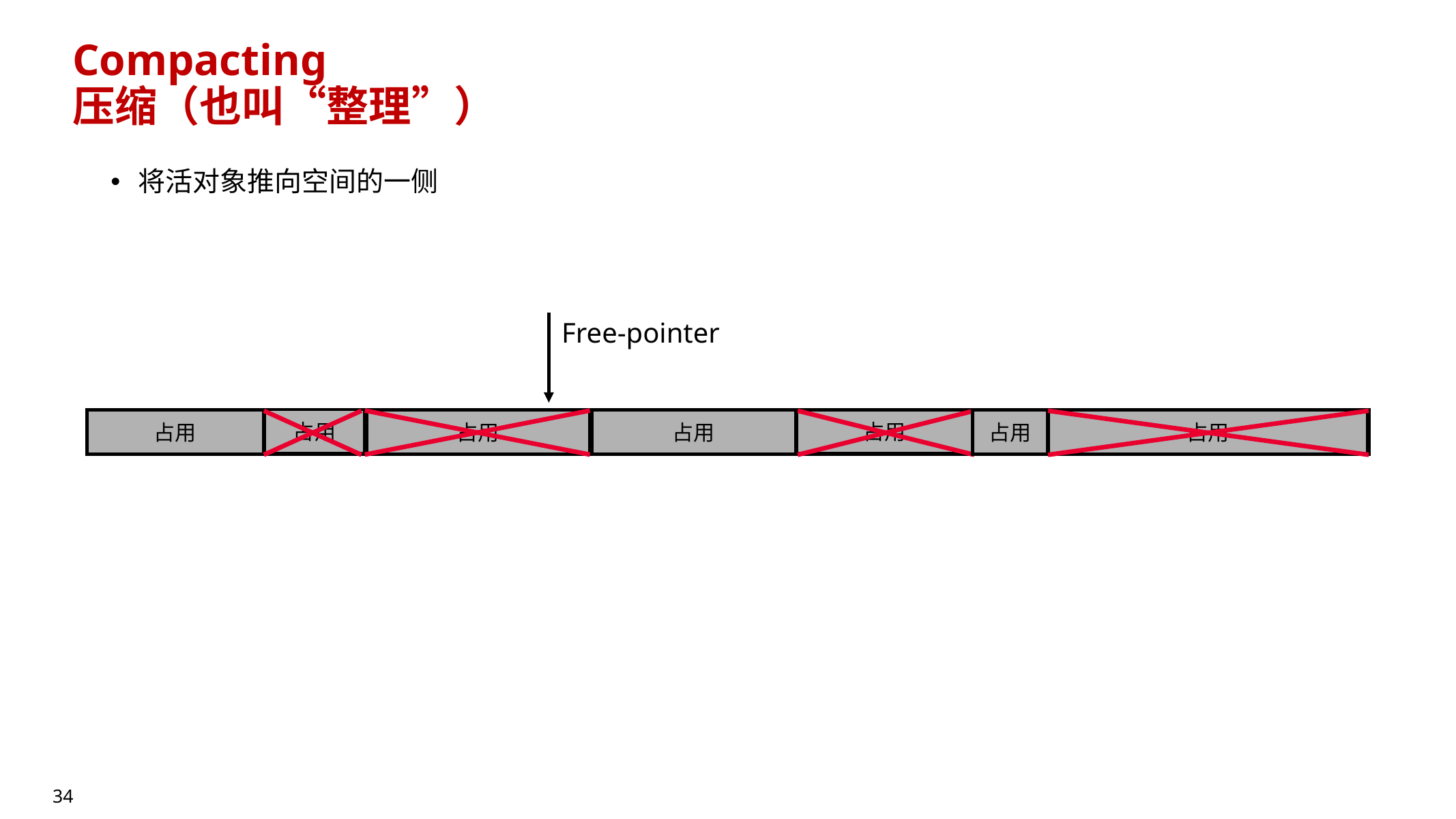
10.6.2 Compaction(压缩/整理)
- 把活对象推向空间一侧,形成连续空闲空间
- 优点:能解决碎片、提高内存利用率
- 缺点:需要搬移对象且地址可能重叠,搬移成本通常较高
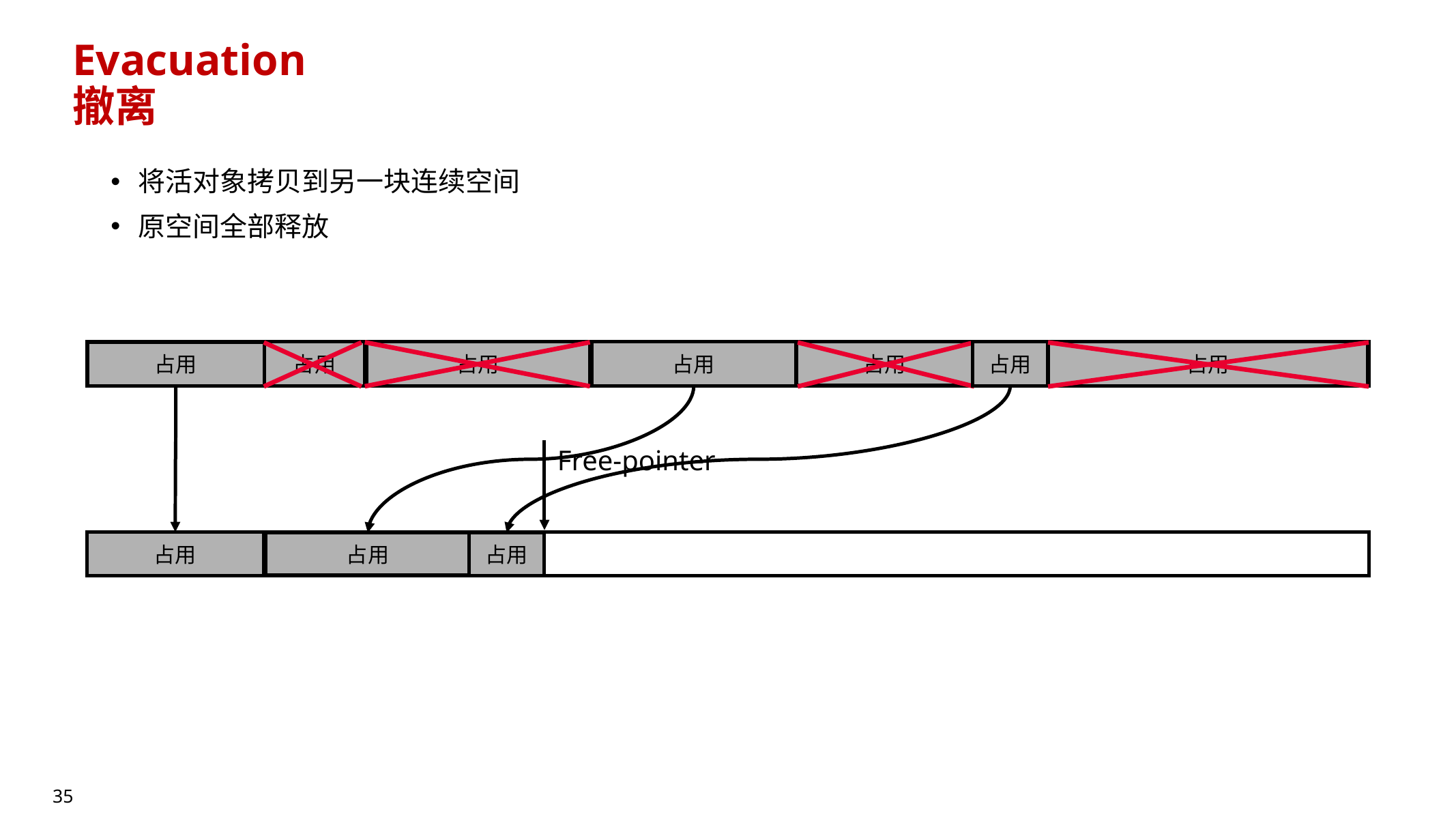
10.6.3 Evacuation(撤离/拷贝,Copying)
- 把活对象拷贝到另一块连续空间(to-space),原空间整体释放(from-space)
- 优点:拷贝通常比 compaction 更快(地址不重叠),适配 bump-pointer 分配
- 缺点:需要额外空间(to-space),可能造成**内存峰值(peak)**更高
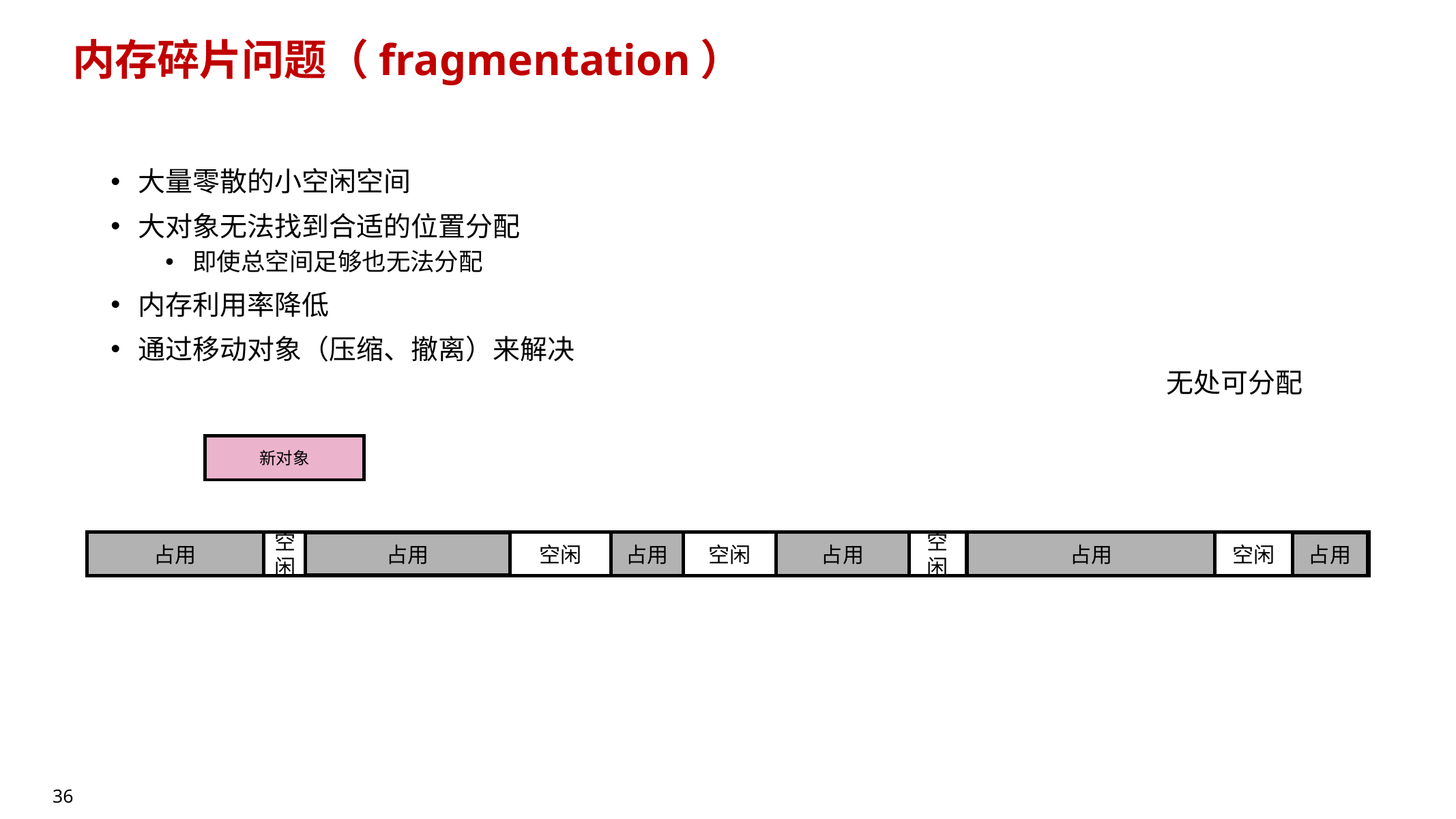
10.6.4 内存碎片问题(Fragmentation)🔥
- 大量零散小空闲块,导致大对象找不到连续空间
- 即使总空闲空间够,也可能无法分配 → 利用率下降
- compaction / evacuation 是解决碎片的核心手段
10.6.5 回收方式比较(需要会“为什么”)
- Sweep:快(不拷贝),但碎片严重
- Compaction:省空间,碎片少,但搬移慢(重叠搬移)
- Evacuation:相对快,但需要额外空间(峰值更高)
10.7 分块(Region-based)与内存搬移策略:峰值与尾延迟
- 分块 GC 的思想:块内 bump-pointer,块级回收(整块回收很快)
- 但如果块里活对象零散,就需要整理碎片:
- 内存整理(compaction):搬到空间一侧
- 内存复制(copying):搬到新块(to-region)
重要工程差异:
- compaction 的“削峰”优势:from-region 被搬空后可立即重新用于分配 → 内存峰值更低
- copying 的峰值问题:from-space 的活对象在 to-space 有一份拷贝,旧空间在 GC 完成前不能释放 → 峰值更高
- 峰值升高会导致堆提前耗尽 → allocation stall → 可能触发 STW GC → 尾延迟(tail latency)变差
这也是为什么“并发复制 GC”虽然延迟低,但峰值控制很关键;而“并发整理 GC”在峰值上可能更有优势。
10.8 分代垃圾回收(Generational GC)🔥
10.8.1 分代假设:新生儿死亡率(Infant Mortality)
经验规律(绝大多数程序符合):
- 大多数对象很快死亡
- 少数对象活得很久
因此策略:
- 经常在“新对象区域”里找垃圾
- 尽量少扫描老年代(因为老对象不太可能突然变垃圾)
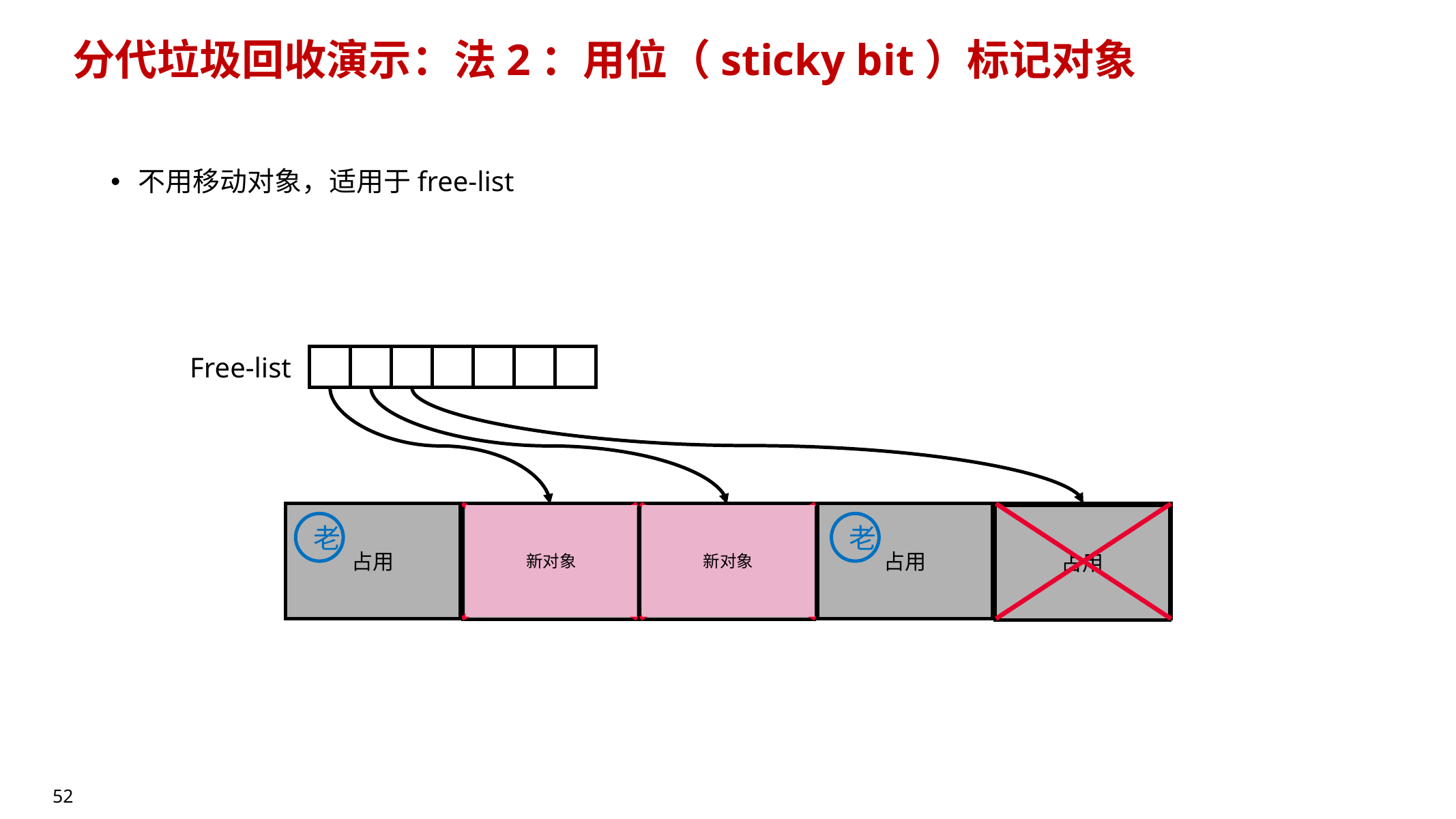
10.8.2 三种典型的分代组织方式(PPT 给了 3 种“演示法”)
- 按代分割区域(类似 semi-space,但不同代大小不同)
- sticky bit(粘滞位) 标记对象是否“老”
- 不移动对象,适用于 free-list
- 不同 region 扮演不同角色(每个 region 有“年代标签”)
- 典型:G1(Garbage First)把堆分成很多 region,动态选择哪些 region 做 young/old/collection set
10.8.3 Remembered Set(记忆集)与写屏障(Write Barrier)🔥
核心问题:
- 如果只扫描 young generation,会漏掉“老对象指向年轻对象”的边
但这条边会使年轻对象成为活对象
解决:
- 维护 Remembered Set(RemSet):记住哪些“老 → 年轻”的引用关系存在
- 当发生写操作
oldObj.field = youngObj时,通过写屏障把该老对象(或该 card)记录进 RemSet

典型伪码(概念):
1 | storeObjectField(object, field, target) { |
10.8.4 分代下的算法组合(年轻代 vs 老年代)
- 年轻代(young):
- 常用 copying/evacuation:因为对象多“早死”,拷贝存活者代价小,且适配 bump-pointer
- 老年代(old/tenured):
- 常用 mark-sweep 或 mark-compact
- 典型组合(PPT 提到的风格):
- Generational mark-sweep:young evacuation + old mark-sweep
- mark-compact:tenured 用 compact,survivor 用 evacuation 等
10.9 并行 GC 与并发 GC(Parallel vs Concurrent)🔥
10.9.1 角色区分:Mutator vs Collector
- Mutator(赋值器):应用线程
- 会改变对象图结构:增加/删除/修改引用边
- Collector(回收器):GC 线程
- 不应改变对象图的“语义结构”(但可能搬移对象、更新指针,属于实现层面的修复)
10.9.2 并行(Parallel)GC:解决吞吐率
- GC 仍是 STW,但用多个 GC 线程并行做扫描/搬移
- 目标:让 GC 本身更快 → 提高吞吐率(throughput)
- 难点:如何把扫描任务均匀分配到多核(典型方案:work-stealing)
10.9.3 并发(Concurrent)GC:解决延迟/卡顿
- GC 线程与 mutator 线程同时运行
- 目标:减少 STW 时间或消除 STW → 降低延迟(latency)
- 注意:并发和并行不冲突,完全可以“又并发又并行”
一句话:
- parallel:让 GC 干得更快(吞吐)
- concurrent:让应用停得更少(延迟)
10.10 并发 GC 的核心难点:三色标记与 Barriers(读/写屏障)🔥🔥
10.10.1 三色标记法(Tri-color Marking)基础
- 白(white):尚未访问(未标记)
- 灰(grey):已发现但其引用对象还未全部扫描(在队列中)
- 黑(black):已扫描完成(其出边都已处理)
并发标记的理想过程:
- 从根把对象放入灰集合
- 逐步扫描灰对象,把可达对象染灰/染黑
- 最终灰集合为空 → 标记结束 → 回收白色对象
10.10.2 并发错误:Mutator 在标记期间“插入边”导致漏标🔥
经典问题(PPT 的图示推演):
- Collector 已把 Obj1 标黑(扫描完它当时的字段)
- Mutator 在此后执行:
Obj1.field1 = Obj3- 如果 Obj3 仍是白色,而 GC 又认为“灰集合为空 -> 结束”,Obj3 会被当作垃圾回收
- 但 mutator 随后读取
Obj1.field1,发现对象不见了 → 错误释放(use-after-free)

要点:Mutator 必须帮助 Collector 正确完成标记。
10.10.3 Barriers:mutator 在读/写时执行的辅助逻辑🔥
- Barrier(屏障):伴随 mutator 的读/写/分配等操作执行的“额外代码”,用于辅助 GC
- 并发标记常见做法:写屏障(write barrier) 在“插入边”时把目标对象置灰/入队
概念伪码(PPT 示意):
1 | storeObjectField(object, field, target) { |

- Barrier 非常影响性能:因为它出现在“写字段/写引用”的热路径上
→ 编译器/JIT/AoT 通常需要:- 内联 fast path
- 尽量用少量指令快速判断是否进入 slow path
- PPT 也强调:barrier 的设计与实现属于 GC 工程的关键点(并给出相关研究论文作为参考)。
同一章里我们已经见过两类 barrier:
- 分代 GC 的写屏障:维护 remembered set(old → young)
- 并发标记的写屏障:维护三色不变量(black 不得直接指向 white)
10.11 编译器/虚拟机需要提供的 GC 支撑机制(Object Map / Stack Map / Safepoint)🔥🔥
PPT 明确强调:编程语言实现中,编译器与垃圾回收是紧耦合的。
GC 要跑得快、停得少,离不开编译器“插桩/元数据”的支持。
10.11.1 Object Map:描述对象内部哪些字段是引用🔥
Object map 的作用:
- 给定某个对象实例,GC 需要知道:
- 哪些 offset 上是引用字段(需要继续追踪)
- 哪些 offset 上是值字段(不追踪)
常见存放位置(PPT 给了多种实现方案):
- 放在类型信息里(如 Type Information Block, TIB)
- 用 bitmap 表示:例如
01001表示哪些字段是引用 - 放在对象头里(每个对象自带)
- 放在全局数组里(按类型编号索引)
“生成 object map 是编译器的责任”,因为编译器最懂对象布局与字段类型。
10.11.2 Stack Map(OpenJDK: OOP map):描述根集合在栈/寄存器中的位置🔥
根集合的一大部分来自“局部变量”,而局部变量可能在:
- 寄存器里
- 栈上的某个位置
并且会随着优化(寄存器分配、SSA、栈帧布局变化)而改变。
因此需要 stack map:
- 在程序的某些位置(safepoint)记录:
- 哪些寄存器含有引用
- 栈上哪些 slot 含有引用
- 哪些变量已经“死了”(liveness)
没有 stack map,GC 就无法可靠找到 root set → tracing 就无法正确。
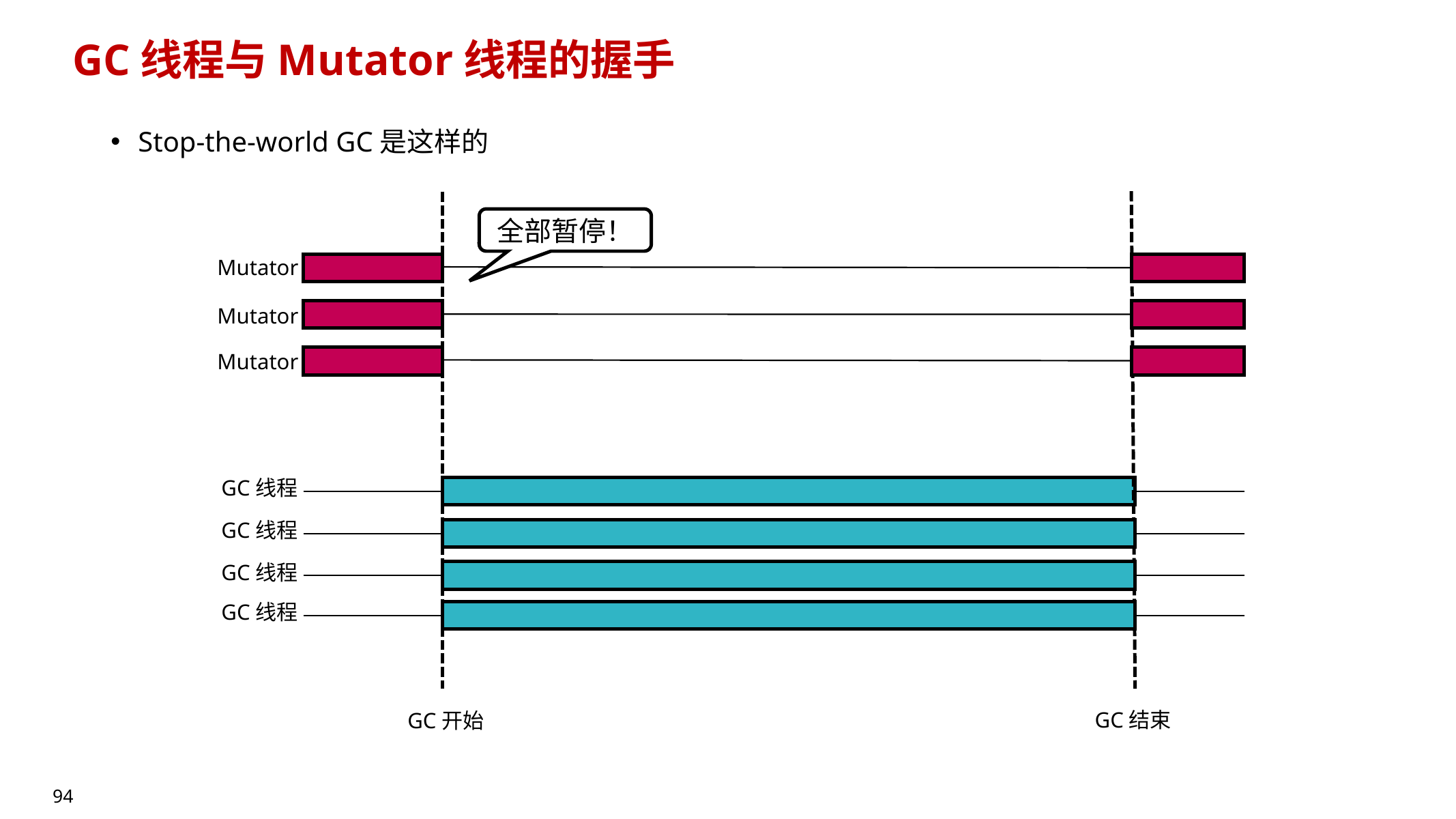
10.11.3 Safepoint(Yieldpoint):mutator 与 GC 的“握手点”🔥
核心事实:
- 应用线程不能在任意位置停下来让 GC 扫描栈,因为可能处于“对 GC 来说不安全”的状态:
- 可能握着锁(如
printf持有 stdout 锁) - 可能在做“对 GC 原子”的操作中间(对象分配写了一半、barrier 执行了一半…)
- UNIX signal 可能把线程停在任意指令中间,甚至导致死锁
- 可能握着锁(如
因此:只能在 safepoint 停止并进行握手。
PPT 的比喻:
- 应用线程像汽车,应用代码像行车道,安全点像红绿灯
不能随便停车,只能在红绿灯处停。
插入位置(PPT 强调的典型点):
- 循环开头/回边:保证大循环里能及时响应 GC
- 函数入口/出口:保证递归/大量调用能及时到达安全点
- 调用点(call sites):天然较安全
10.11.4 GC 与 mutator 的握手(Handshake)🔥
并发 GC 并不是“完全不停”:
- 仍需要在若干阶段短暂同步(握手),完成:
- 扫描栈(收集 root set)
- 传递 mutator 的本地 buffer 给 GC(如 remembered set buffer)
- 在某些算法中切换 barrier 模式(不是所有算法都能切换)
握手通常很短(PPT 提到可做到 1ms 以下),并且可能出现多次(多个 GC 阶段)。

10.11.5 Safepoint 的高效实现:Checking vs Trapping
Safepoint 的特点:
- 非常频繁执行,但极少真正触发
- PPT 给的统计:某些 VM 中 safepoint 每秒可执行到 1e8 次量级,但真正因 GC 触发的比例很低
- 因此 safepoint 必须极低开销(几条指令级别)
两种实现思路:
- Checking:读一个全局/线程局部变量判断是否需要停
- GC 触发时写 1;mutator 在 safepoint 读到 1 就进入慢路径
- Trapping / Page Protection:用
mprotect把某页设为不可读
- 平时读没事;GC 触发时把页保护起来
- mutator 在 safepoint 读该页触发 segfault → 进入处理逻辑

PPT 还给了 x86 / aarch64 的低级指令示意:把 safepoint check 编译成极少的机器指令。
10.11.6 小结:编译器对 GC 的四项核心支持(必须会背)🔥
- 在应用代码中插入高效 barrier(读/写屏障)
- 生成 object map(找到对象内部引用)
- 生成 stack map(找到栈/寄存器中的根引用)
- 插入高效 safepoint(同步 mutator 与 GC)
10.12 仓颉语言:全并发内存整理 GC(Cangjie Concurrent Compacting GC)🔥🔥
PPT 后半部分用仓颉作为“现代高性能 GC 系统”的例子:强调低延迟、低内存占用、编译器-运行时紧耦合。
10.12.1 设计目标与技术特征
- 高性能 + 极低时延(tail latency)
- 内存占用少(峰值控制好)
- 分配快 / barrier 开销低
- 完全并发(fully concurrent)
- 对象基础开销低 / 支持内存整理(compaction)
10.12.2 仓颉对象布局:基础开销对比(Java/Swift)
PPT 对比了不同语言对象头:
- Java(HotSpot 64-bit)传统布局:mark word + klass word(以及压缩 class word 等变体)
- Swift/Objective-C:带强/弱引用计数元数据
- 仓颉:更紧凑的 type info 指针(可压缩),减少对象基础开销(PPT 说可减少近 10%)
10.12.3 仓颉堆布局:RegionInfo + Region
- region 元数据地址与 region 内存地址通过线性关系对应
- 在 region 内通过指针跳跃(bump-pointer)分配小对象
- 分配可做到非常短的机器指令序列(PPT 提到数量级 ~10 条指令)
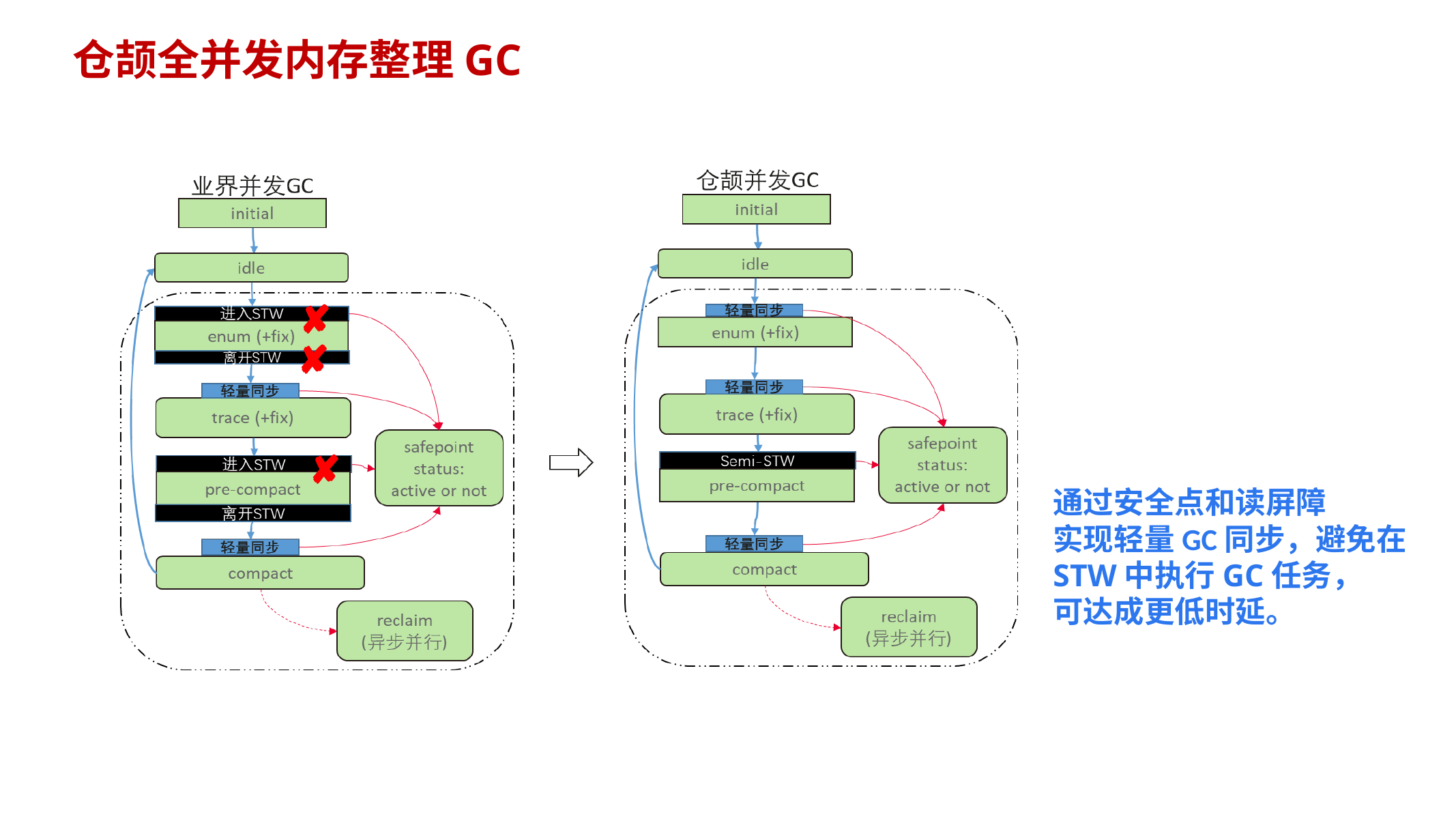
10.12.4 典型“内存整理 GC”的阶段划分(理解流程)
PPT 给了一个典型整理 GC 的阶段机:
- enum:收集 GC 根集合
- trace:根据根与引用关系递归标记活对象
- pre-compact:搬移栈上根引用指向的对象,并更新这些根引用
- compact:搬移 region 内活对象,完成后可回收该 region
- fix:修复堆中的旧引用
- idle:GC 未开始/已完成
10.12.5 “全并发内存整理 GC”:通过 safepoint + 读屏障实现轻量同步
- 目标:避免在 STW 中执行大量 GC 任务,实现更低时延
- 手段:安全点 + 读屏障(load barrier)来保证并发整理下指针读取正确
- 结果:应用线程的暂停时间 ≈ 同步等待时间(短)+(不必)等待 GC 完整任务时间
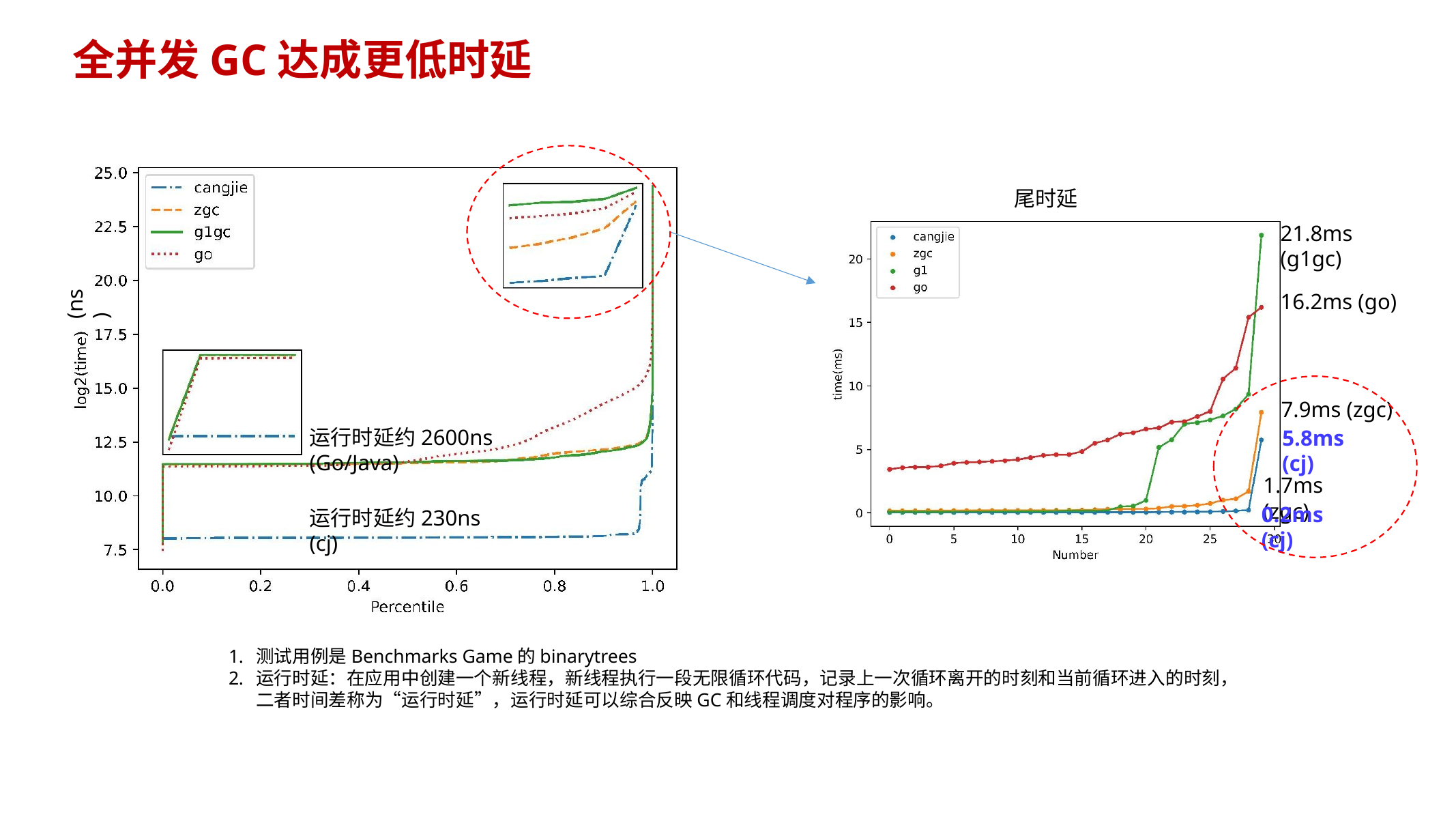
10.12.6 延迟/峰值:为何整理(compaction)能“削峰”
- 整理算法搬走活对象后,from-region 可立即重新用于分配 → 峰值低
- copying 算法需要双份存活对象内存,完成后才能释放旧空间 → 峰值高
- PPT 给出实验:整理能显著降低平均内存用量,并改善尾延迟(以 benchmark 说明)
10.13 进一步优化:屏障快路径、指针标记、逃逸分析(PEA)与标量替换(SROA)
10.13.1 读/写屏障的快路径内联
- 读屏障(load barrier)伪码:
1 | LoadObjectField(obj, field) { |
- 写屏障(store barrier)伪码(可能有 pre/post):
1 | StoreObjectField(obj, field, target) { |
关键优化点:
- 根据 object/field/target 的“状态”快速判断是否进入 slow path
- 编译器会尽量把 fast path 内联成极短分支(热路径不跳 slow path)
- 课件还给了一个常见工程技巧:把 field 存成“tag + address”的联合体(示意:
tag:16 + address:48),tag==0直接返回地址;tag!=0才走readfieldslow();- 写屏障也可通过
gc_is_running等全局/线程态位快速判定是否需要 slow path。
10.13.2 指针标记(Pointer Tagging):区分 bad pointer / good pointer🔥
并发整理下的典型风险:
- 活对象被搬移到了新地址
object3' - 旧地址处的内存可能被回收并重用于新对象
object x - 若某引用仍指向旧地址,就会变成 bad pointer(指向错误对象)
解决思路:
- 在指针中编码状态(利用 64 位平台指针对齐带来的低位空闲位/高位保留位)
- 用 tag 区分:
- good pointer
- previous GC 的 bad pointer
- current GC 的 bad pointer
- 课件还展示了一种“乒乓(ping-pong)编码”思路:用
V与~V轮流表示 previous/current GC 的坏指针状态 - 通过读屏障识别并修复(把 bad pointer 修成指向新位置)
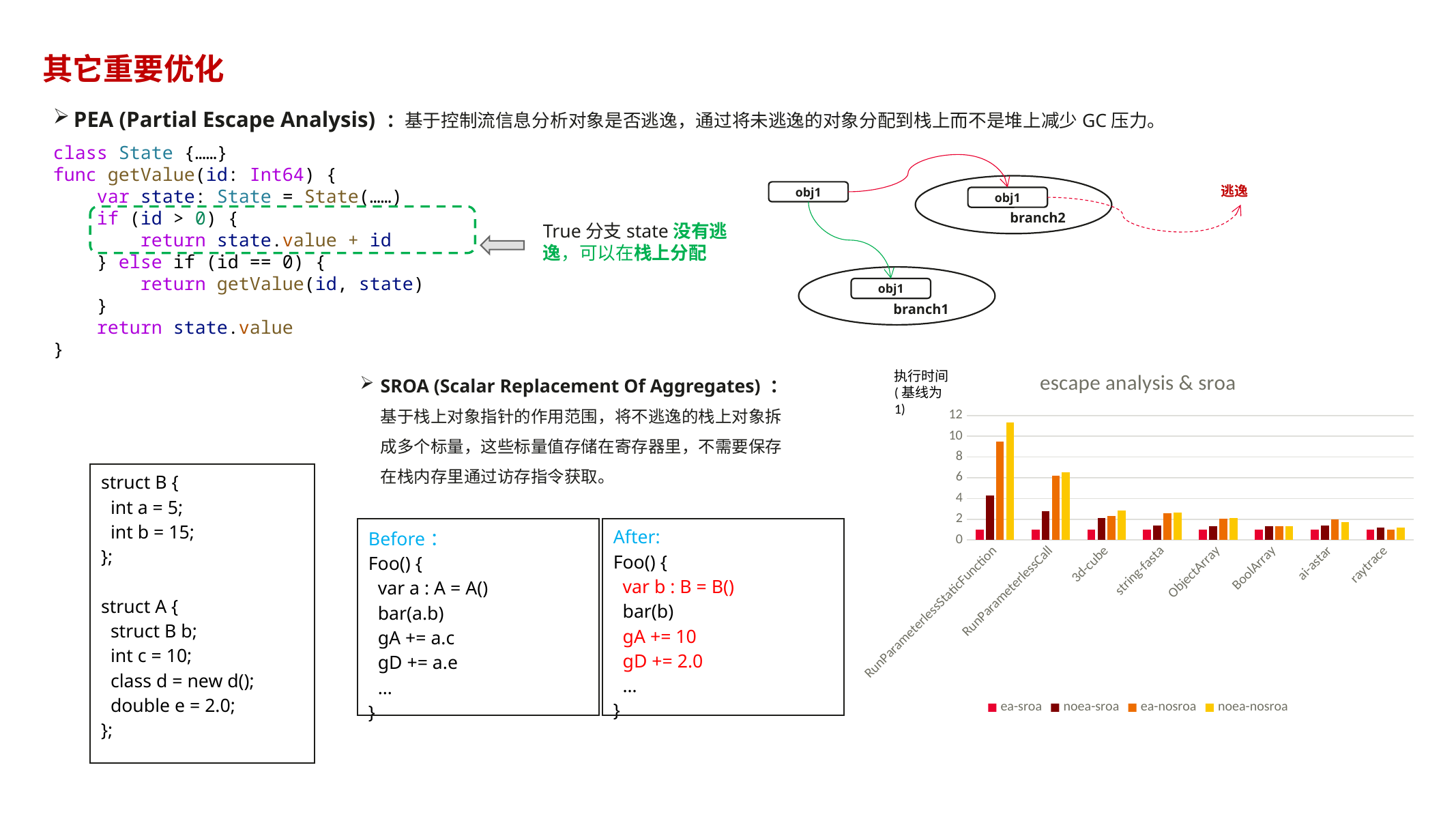
10.13.3 PEA(Partial Escape Analysis)与 SROA(Scalar Replacement of Aggregates)
- PEA(部分逃逸分析):分析对象是否逃逸当前作用域/线程
- 不逃逸 → 可分配到栈上(减少堆分配与 GC 压力)
- SROA(标量替换):把不逃逸的聚合对象拆成若干标量
- 标量放寄存器里,进一步减少内存访问与栈负担
这两项优化体现了“编译器与 GC 必须紧耦合”:优化能显著降低 GC 工作量。
10.14 手工内存管理 vs 自动内存管理:第三条路径(Rust Ownership)
PPT 最后对比提出:除了“手工 free”与“运行时 GC”,还有第三条路径:
- 类型系统 + 编译器静态保证内存安全(无需运行时 GC)
- Rust 的核心约束可以概括为:
- 每个资源有唯一 owner
- 其他人只能 borrow(借用)
- 当存在借用时,owner 不能释放或(可变借用时)随意修改
- 从而达成:memory safety + data-race freedom(在语言规则范围内)

10.14.1 Ownership(唯一所有权)与 Move
let res = Box::new(...):res 拥有堆资源- res 离开作用域自动释放
take(res)会发生 move:所有权从 res 移到 arg- res 不再可用(编译错误),避免悬垂引用/双重释放
10.14.2 Lifetime(生命周期)静态检查
- 编译器在编译期推断/检查引用有效期
- 超出有效期继续使用会编译失败(而不是运行时崩溃)
10.14.3 Borrowing:共享借用 & 可变借用(Aliasing vs Mutation)🔥
- 共享借用
&T:允许多个别名同时存在,但只读
→ 解决 aliasing - 可变借用
&mut T:允许修改,但同一时间只能有一个可变借用
→ 避免“别名 + 修改”同时出现(经典并发/内存错误根源)
PPT 用“Aliasing / Mutation”二维约束总结 Rust:
- 允许 aliasing 时不允许 mutation
- 允许 mutation 时不允许 aliasing
以此避免数据竞争与悬垂问题。
10.15 本章速记与典型问法(考前背诵版)
- 垃圾判定:从 root set 出发不可达 = 垃圾(reachability)
- Tracing vs RC:
- tracing:能处理环;但若全堆扫描成本大 → 分代
- RC:可及时回收;但不能处理环;同步释放也可能卡顿
- 回收策略:
- sweep:快但碎片
- compaction:碎片少但搬移慢
- evacuation/copy:快但峰值高
- 分代 GC:年轻代频繁收、老年代少扫;写屏障维护 remembered set
- 并行 vs 并发:
- parallel:吞吐(GC 更快)
- concurrent:延迟(STW 更少)
- 并发标记的正确性:三色标记 + barrier 维持不变量
- 编译器/VM 必备支撑:barrier + object map + stack map + safepoint
- 仓颉全并发整理:低延迟、低峰值;safepoint+读屏障;指针标记辅助修复
- Rust 第三路径:ownership/borrowing 静态保证资源安全,减少/避免 GC
 微信
微信 支付宝
支付宝

